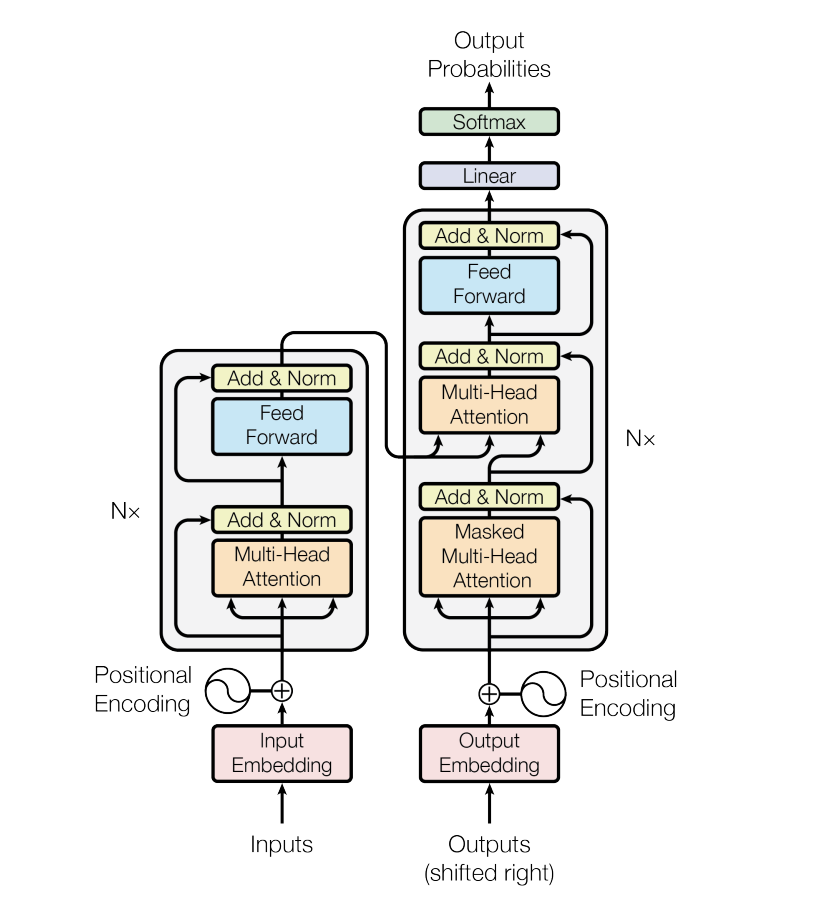
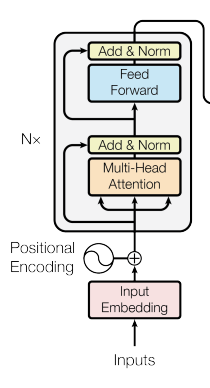
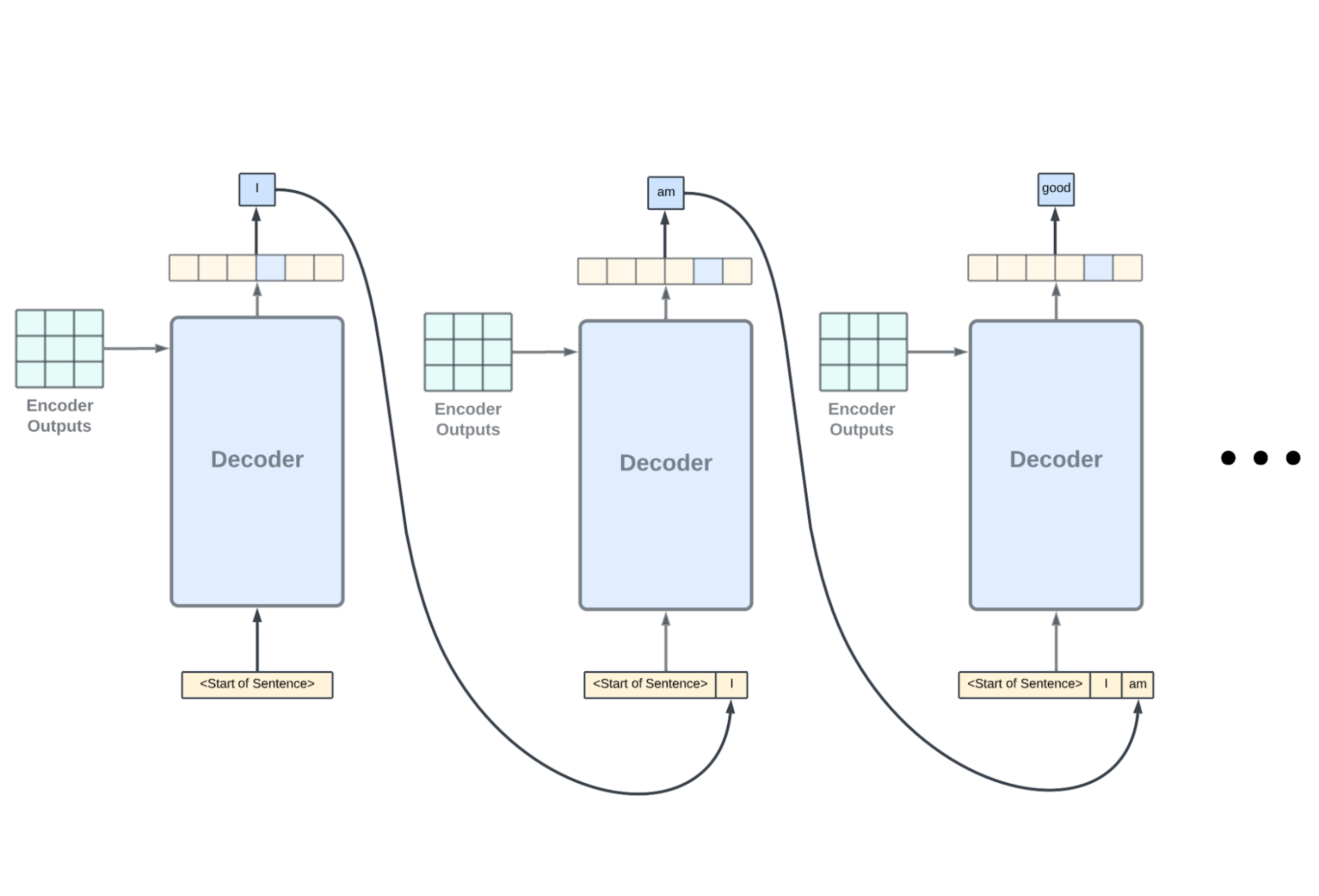
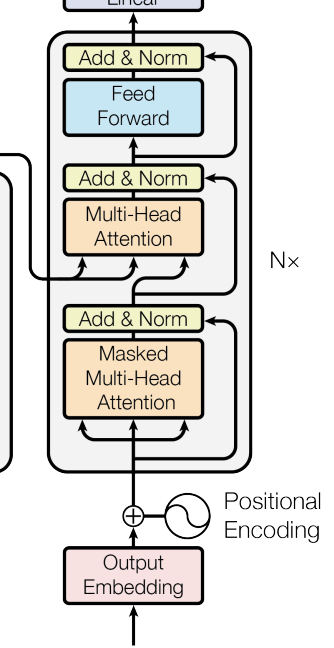
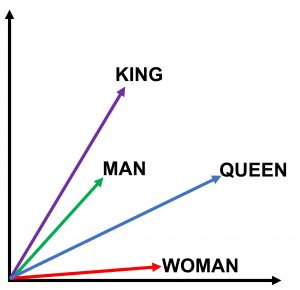
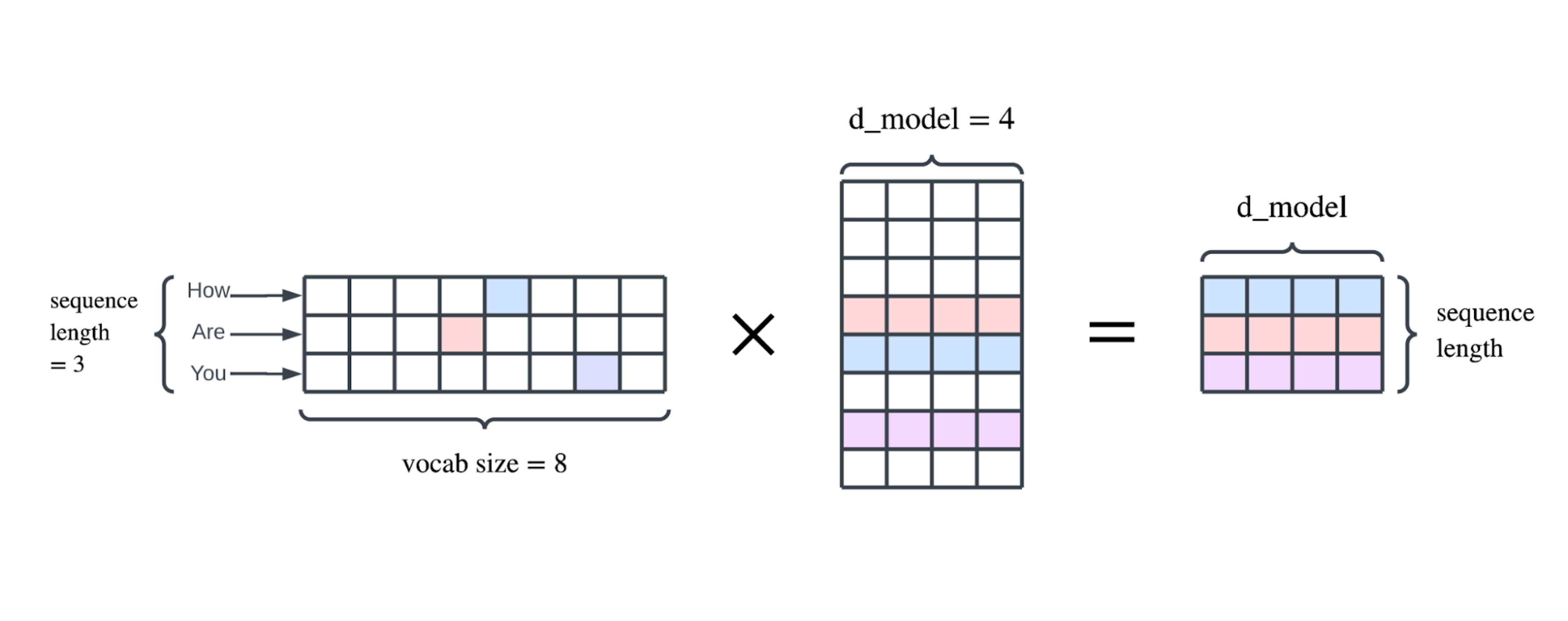
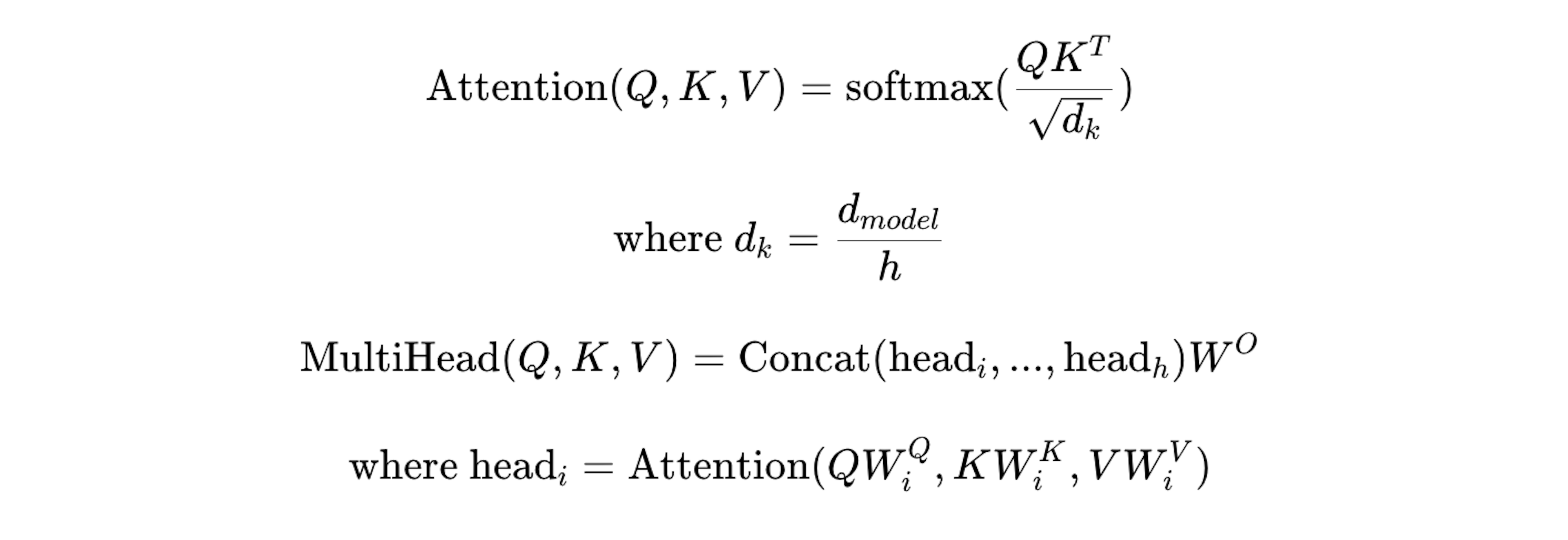第一节 引言
第二节 简化代码实现Pytorch版本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import torchimport torch.nn as nnclass Transformer (nn.Module): def __init__ (self, input_dim, output_dim, hidden_dim, num_layers ): super (Transformer, self).__init__() self.encoder = nn.TransformerEncoderLayer(input_dim, hidden_dim, num_layers) self.decoder = nn.TransformerDecoderLayer(output_dim, hidden_dim, num_layers) def forward (self, src, tgt ): enc_output = self.encoder(src) dec_output = self.decoder(tgt, enc_output) return dec_output input_dim = 100 output_dim = 200 hidden_dim = 256 num_layers = 4 model = Transformer(input_dim, output_dim, hidden_dim, num_layers) src = torch.randn(50 , input_dim) tgt = torch.randn(60 , output_dim) output = model(src, tgt)
编码器接收输入,而解码器输出预测。
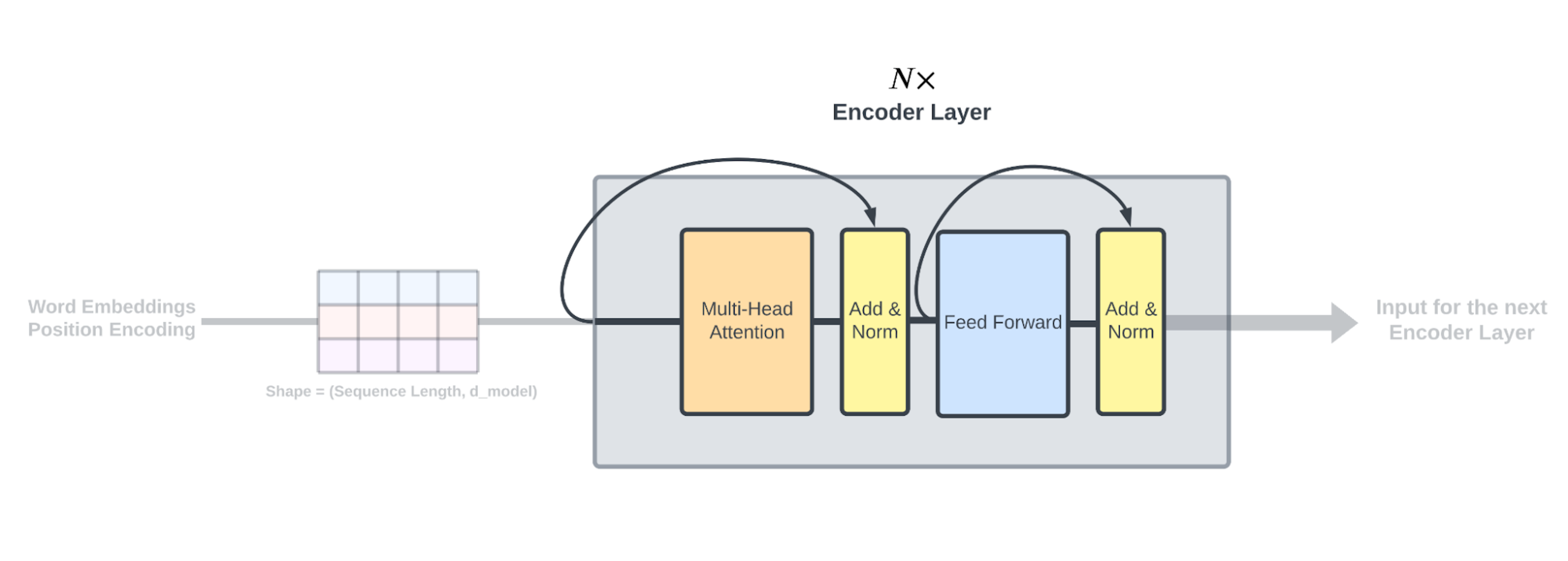
第二节 编码器 2.2.1 编码器原理
因此,TransformerEncoder由以下三个主要部分组成:
Embedding层(将单词ID序列转换为单词的分布表示)
Positional Encoding层
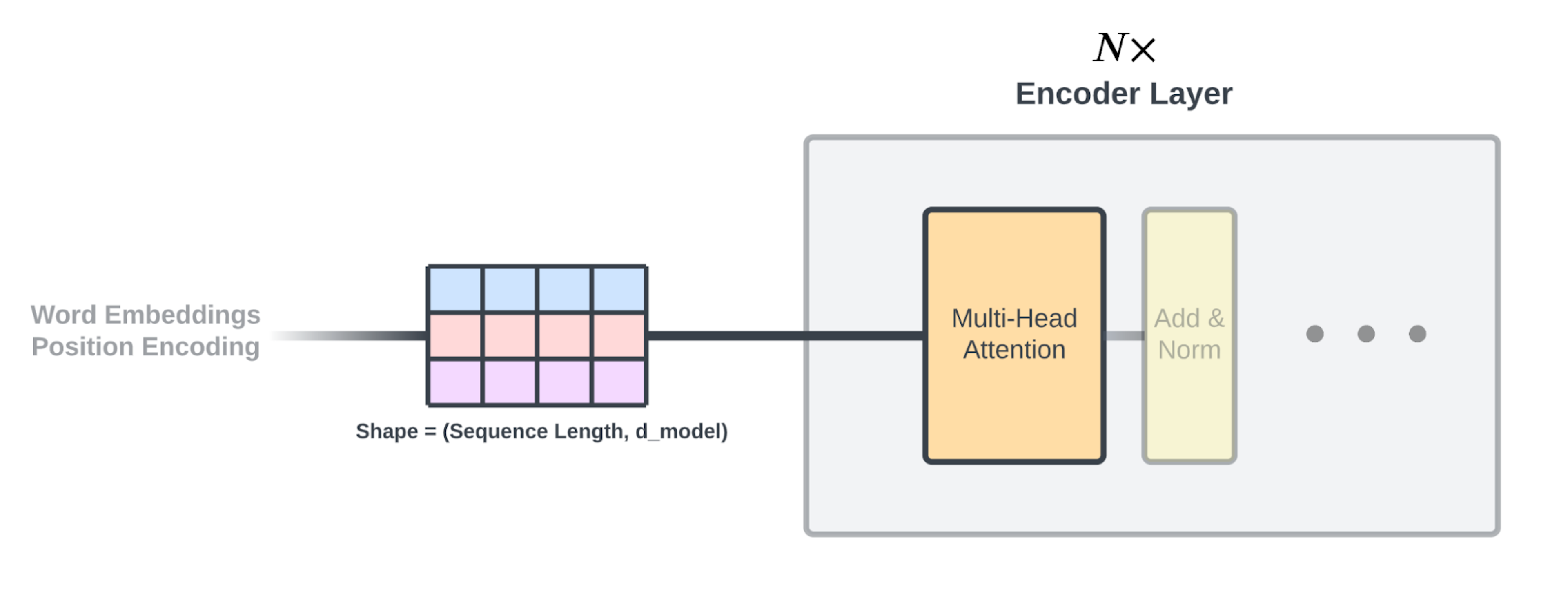
由任意N层堆叠的TransformerEncoderBlock层,包括Multihead Attention和FeedForward Network(每层都应用Add & Norm)
2.2.2 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 import torchfrom torch import nnfrom torch.nn import LayerNormfrom .Embedding import Embeddingfrom .FFN import FFNfrom .MultiHeadAttention import MultiHeadAttentionfrom .PositionalEncoding import AddPositionalEncodingclass TransformerEncoderLayer (nn.Module): def __init__ ( self, d_model: int , d_ff: int , heads_num: int , dropout_rate: float , layer_norm_eps: float , ) -> None : super ().__init__() self.multi_head_attention = MultiHeadAttention(d_model, heads_num) self.dropout_self_attention = nn.Dropout(dropout_rate) self.layer_norm_self_attention = LayerNorm(d_model, eps=layer_norm_eps) self.ffn = FFN(d_model, d_ff) self.dropout_ffn = nn.Dropout(dropout_rate) self.layer_norm_ffn = LayerNorm(d_model, eps=layer_norm_eps) def forward (self, x: torch.Tensor, mask: torch.Tensor = None ) -> torch.Tensor: x = self.layer_norm_self_attention(self.__self_attention_block(x, mask) + x) x = self.layer_norm_ffn(self.__feed_forward_block(x) + x) return x def __self_attention_block (self, x: torch.Tensor, mask: torch.Tensor ) -> torch.Tensor: x = self.multi_head_attention(x, x, x, mask) return self.dropout_self_attention(x) def __feed_forward_block (self, x: torch.Tensor ) -> torch.Tensor: return self.dropout_ffn(self.ffn(x)) class TransformerEncoder (nn.Module): def __init__ ( self, vocab_size: int , max_len: int , pad_idx: int , d_model: int , N: int , d_ff: int , heads_num: int , dropout_rate: float , layer_norm_eps: float , device: torch.device = torch.device("cpu" ) -> None : super ().__init__() self.embedding = Embedding(vocab_size, d_model, pad_idx) self.positional_encoding = AddPositionalEncoding(d_model, max_len, device) encodelayerList = [TransformerEncoderLayer(d_model, d_ff, heads_num, dropout_rate, layer_norm_eps) for _ in range (N)] self.encoder_layers = nn.ModuleList(encodelayerList) def forward (self, x: torch.Tensor, mask: torch.Tensor = None ) -> torch.Tensor: x = self.embedding(x) x = self.positional_encoding(x) for encoder_layer in self.encoder_layers: x = encoder_layer(x, mask) return x
第三节 解码器 2.3.1 解码器原理
Decoder与Encoder一样,由Embedding、Positional Encoding、Multihead Attention、FeedForward Network组成。
2.3.2 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 import torchfrom torch import nnfrom torch.nn import LayerNormfrom .Embedding import Embeddingfrom .FFN import FFNfrom .MultiHeadAttention import MultiHeadAttentionfrom .PositionalEncoding import AddPositionalEncodingclass TransformerDecoderLayer (nn.Module): def __init__ ( self, d_model: int , d_ff: int , heads_num: int , dropout_rate: float , layer_norm_eps: float , ): super ().__init__() self.self_attention = MultiHeadAttention(d_model, heads_num) self.dropout_self_attention = nn.Dropout(dropout_rate) self.layer_norm_self_attention = LayerNorm(d_model, eps=layer_norm_eps) self.src_tgt_attention = MultiHeadAttention(d_model, heads_num) self.dropout_src_tgt_attention = nn.Dropout(dropout_rate) self.layer_norm_src_tgt_attention = LayerNorm(d_model, eps=layer_norm_eps) self.ffn = FFN(d_model, d_ff) self.dropout_ffn = nn.Dropout(dropout_rate) self.layer_norm_ffn = LayerNorm(d_model, eps=layer_norm_eps) def forward ( self, tgt: torch.Tensor, src: torch.Tensor, mask_src_tgt: torch.Tensor, mask_self: torch.Tensor, ) -> torch.Tensor: tgt = self.layer_norm_self_attention( tgt + self.__self_attention_block(tgt, mask_self) ) x = self.layer_norm_src_tgt_attention( tgt + self.__src_tgt_attention_block(src, tgt, mask_src_tgt) ) x = self.layer_norm_ffn(x + self.__feed_forward_block(x)) return x def __src_tgt_attention_block ( self, src: torch.Tensor, tgt: torch.Tensor, mask: torch.Tensor ) -> torch.Tensor: return self.dropout_src_tgt_attention( self.src_tgt_attention(tgt, src, src, mask) ) def __self_attention_block ( self, x: torch.Tensor, mask: torch.Tensor ) -> torch.Tensor: return self.dropout_self_attention(self.self_attention(x, x, x, mask)) def __feed_forward_block (self, x: torch.Tensor ) -> torch.Tensor: return self.dropout_ffn(self.ffn(x)) class TransformerDecoder (nn.Module): def __init__ ( self, tgt_vocab_size: int , max_len: int , pad_idx: int , d_model: int , N: int , d_ff: int , heads_num: int , dropout_rate: float , layer_norm_eps: float , device: torch.device = torch.device("cpu" ) -> None : super ().__init__() self.embedding = Embedding(tgt_vocab_size, d_model, pad_idx) self.positional_encoding = AddPositionalEncoding(d_model, max_len, device) decodeLayerList = [ TransformerDecoderLayer( d_model, d_ff, heads_num, dropout_rate, layer_norm_eps ) for _ in range (N) ] self.decoder_layers = nn.ModuleList(decodeLayerList) def forward ( self, tgt: torch.Tensor, src: torch.Tensor, mask_src_tgt: torch.Tensor, mask_self: torch.Tensor, ) -> torch.Tensor: tgt = self.embedding(tgt) tgt = self.positional_encoding(tgt) for decoder_layer in self.decoder_layers: tgt = decoder_layer( tgt, src, mask_src_tgt, mask_self, ) return tgt
第四节 词嵌入
词嵌入可视为语言模型预训练技术,如果不用嵌入技术的话其实模型在训练时也可以学到每个单词上下文信息,只不过词嵌入可提前完成。
第五节 位置编码 2.5.1 位置编码原理
$$
正弦位置编码具有几个优点:
原始论文中已经指出,Transformer 能够利用位置编码函数“推断出比训练期间遇到的序列长度更长的序列”。
单词之间的相对位置可以推断出来,因为对于位置彼此接近的单词,它们的位置编码向量也会相似。
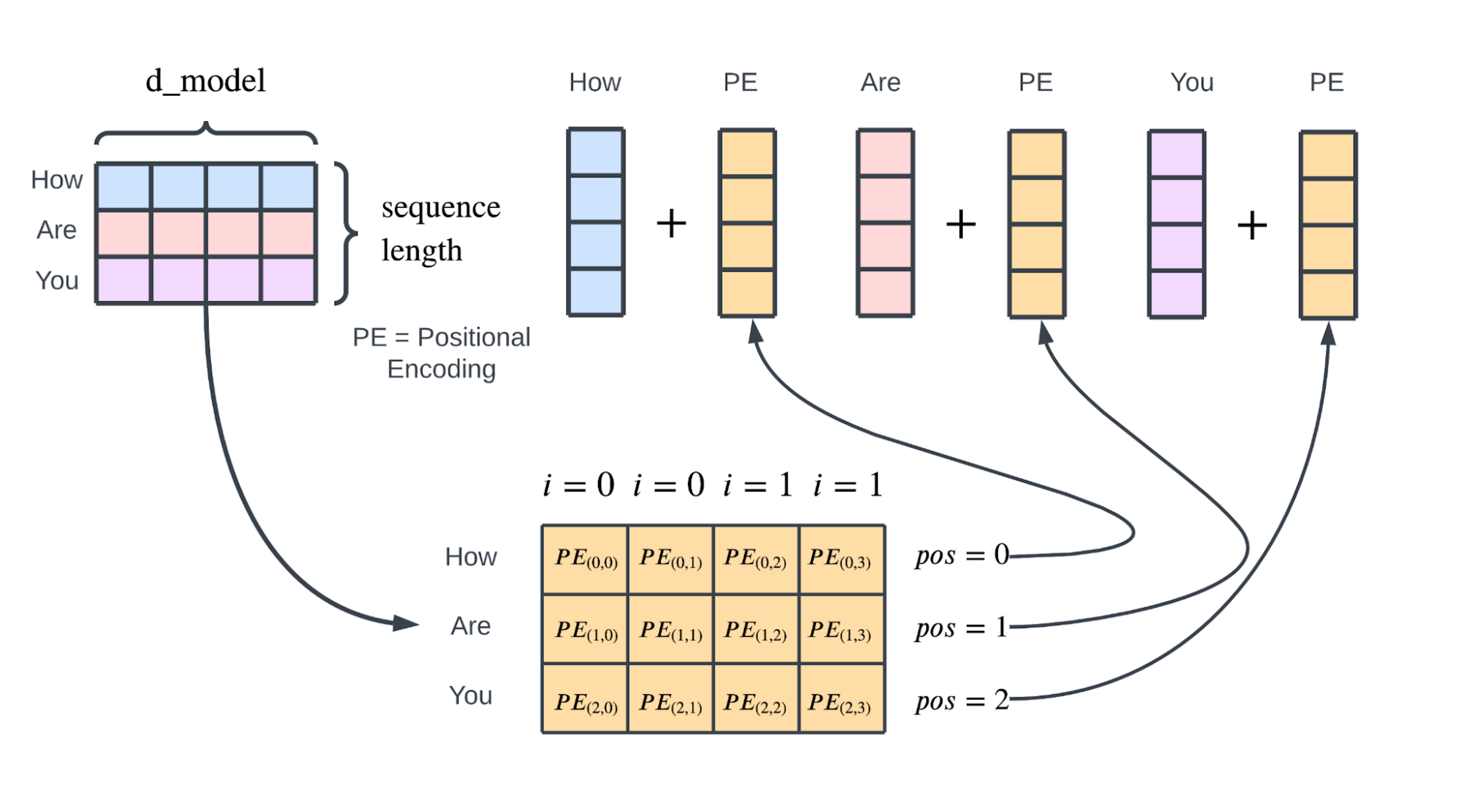
位置编码组件之后,其形状为(序列长度,$d_{model}$)的输出将被传递到由自注意力块和前馈神经网络组成的第一个编码器层。
请注意,解码器的输入序列也使用相同的预处理方案(词嵌入和位置编码),我们将在后面讨论。
2.5.2 具体计算例子
词语和其位置 :
“我”:位置 0
“去”:位置 1
“打”:位置 2
“篮球”:位置 3
嵌入维度 $d_{model}$ 是 4,所以我们有 $i = 0, 1$
位置编码计算
位置 0 (“我”):
$i = 0$:
$PE(0, 0) = \sin\left(\frac{0}{10000^{\frac{0}{4}}}\right) = \sin(0) = 0$
$PE(0, 1) = \cos\left(\frac{0}{10000^{\frac{0}{4}}}\right) = \cos(0) = 1$
$i = 1$:
$PE(0, 2) = \sin\left(\frac{0}{10000^{\frac{2}{4}}}\right) = \sin(0) = 0$
$PE(0, 3) = \cos\left(\frac{0}{10000^{\frac{2}{4}}}\right) = \cos(0) = 1$
结果:$[0, 1, 0, 1]$
位置 1 (“去”)
$i = 0$:
$PE(1, 0) = \sin\left(\frac{1}{10000^{\frac{0}{4}}}\right) = \sin(1) \approx 0.8415$
$PE(1, 1) = \cos\left(\frac{1}{10000^{\frac{0}{4}}}\right) = \cos(1) \approx 0.5403$
$i = 1$:
$PE(1, 2) = \sin\left(\frac{1}{10000^{\frac{2}{4}}}\right) = \sin(0.0001) \approx 0.0001$
$PE(1, 3) = \cos\left(\frac{1}{10000^{\frac{2}{4}}}\right) = \cos(0.0001) \approx 1.0000$
结果:$[0.8415, 0.5403, 0.0001, 1.0000]$
位置 2 (“打”)
$i = 0$:
$PE(2, 0) = \sin\left(\frac{2}{10000^{\frac{0}{4}}}\right) = \sin(2) \approx 0.9093$
$PE(2, 1) = \cos\left(\frac{2}{10000^{\frac{0}{4}}}\right) = \cos(2) \approx -0.4161$
$i = 1$:
$PE(2, 2) = \sin\left(\frac{2}{10000^{\frac{2}{4}}}\right) = \sin(0.0002) \approx 0.0002$
$PE(2, 3) = \cos\left(\frac{2}{10000^{\frac{2}{4}}}\right) = \cos(0.0002) \approx 0.9999$
结果:$[0.9093, -0.4161, 0.0002, 0.9999]$
位置 3 (“篮球”)
$i = 0$:
$PE(3, 0) = \sin\left(\frac{3}{10000^{\frac{0}{4}}}\right) = \sin(3) \approx 0.1411$
$PE(3, 1) = \cos\left(\frac{3}{10000^{\frac{0}{4}}}\right) = \cos(3) \approx -0.9899$
$i = 1$:
$PE(3, 2) = \sin\left(\frac{3}{10000^{\frac{2}{4}}}\right) = \sin(0.0003) \approx 0.0003$
$PE(3, 3) = \cos\left(\frac{3}{10000^{\frac{2}{4}}}\right) = \cos(0.0003) \approx 0.9999$
结果:$[0.1411, -0.9899, 0.0003, 0.9999]$
位置编码结果表格:
位置
单词
$PE(pos, 0)$
$PE(pos, 1)$
$PE(pos, 2)$
$PE(pos, 3)$
0
我
0.0000
1.0000
0.0000
1.0000
1
去
0.8415
0.5403
0.0001
1.0000
2
打
0.9093
-0.4161
0.0002
0.9999
3
篮球
0.1411
-0.9899
0.0003
0.9999
2.5.3 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import numpy as npimport torchfrom torch import nnclass AddPositionalEncoding (nn.Module): def __init__ ( self, d_model: int , max_len: int , device: torch.device = torch.device("cpu" ) -> None : super ().__init__() self.d_model = d_model self.max_len = max_len positional_encoding_weight: torch.Tensor = self._initialize_weight().to(device) self.register_buffer("positional_encoding_weight" , positional_encoding_weight) def forward (self, x: torch.Tensor ) -> torch.Tensor: seq_len = x.size(1 ) return x + self.positional_encoding_weight[:seq_len, :].unsqueeze(0 ) def _get_positional_encoding (self, pos: int , i: int ) -> float : w = pos / (10000 ** (((2 * i) // 2 ) / self.d_model)) if i % 2 == 0 : return np.sin(w) else : return np.cos(w) def _initialize_weight (self ) -> torch.Tensor: positional_encoding_weight = [ [self._get_positional_encoding(pos, i) for i in range (1 , self.d_model + 1 )] for pos in range (1 , self.max_len + 1 ) ] return torch.tensor(positional_encoding_weight).float ()
第六节 注意力机制 2.6.1 注意力机制原理
2.6.2 注意力机制背后的数学原理
第七节 缩放点积注意力(Scaled Dot-Product Attention) 2.7.1 缩放点积注意力原理
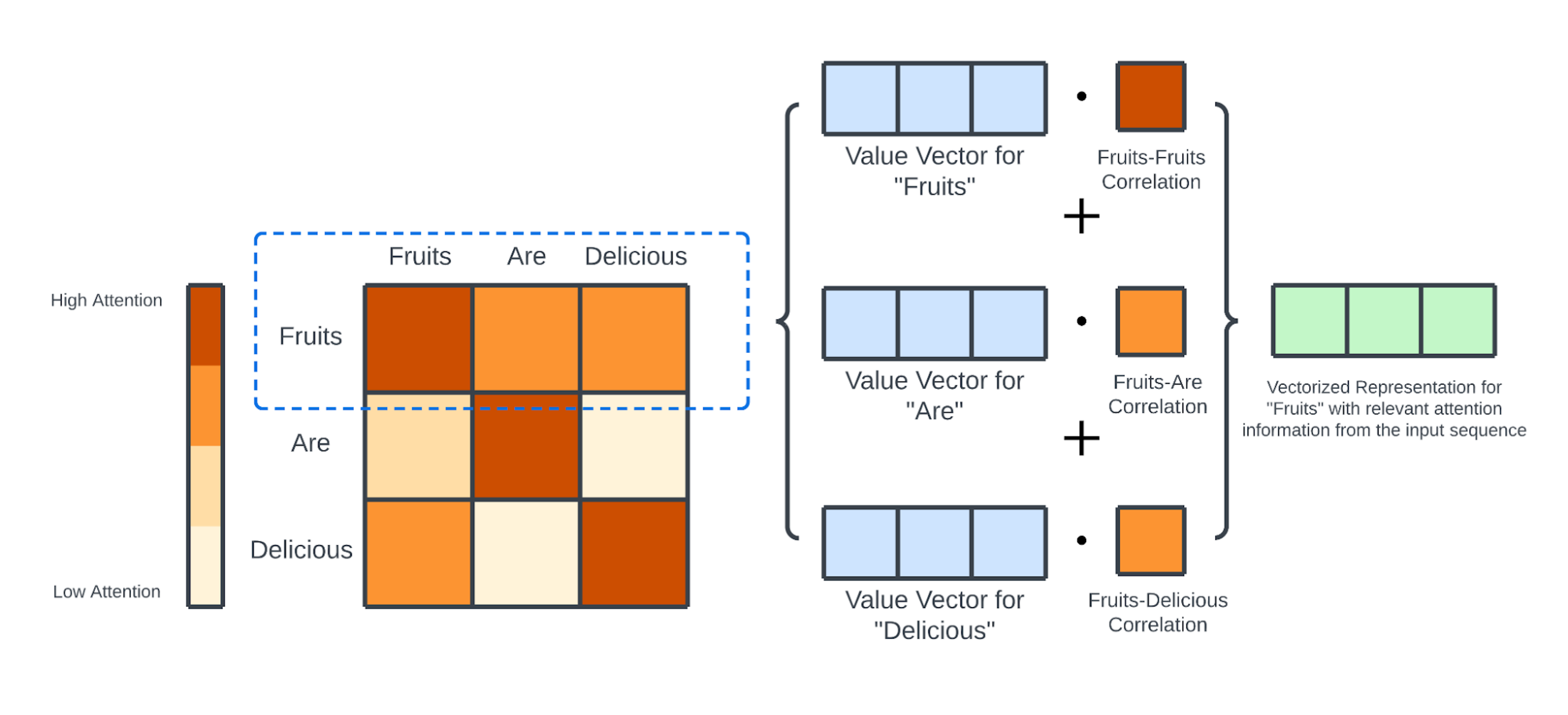
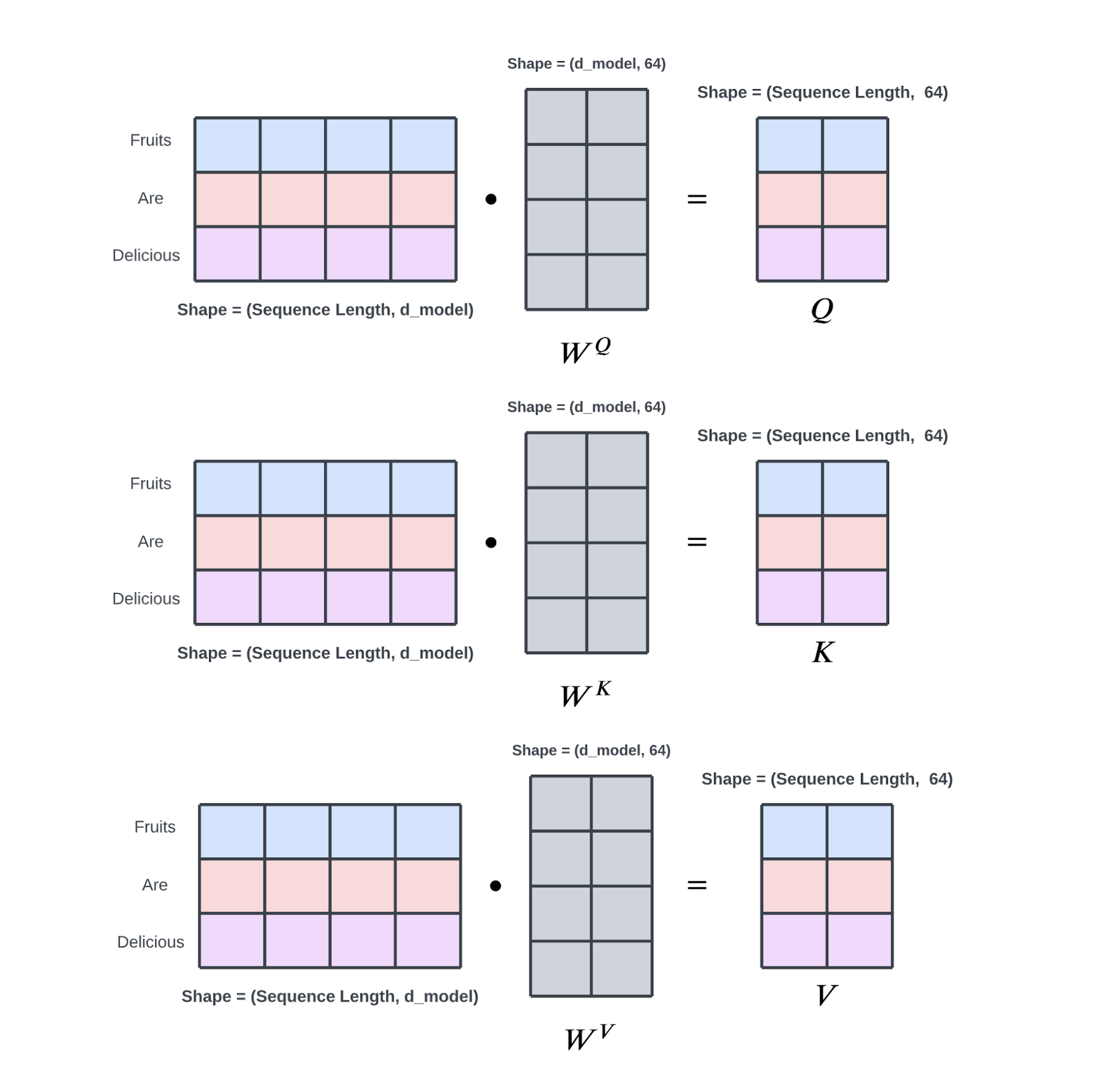
Q查询矩阵 对应的是 Q查询 中单词的矢量化表示,K键矩阵 对应的是 K键 中单词的矢量化表示,所以:
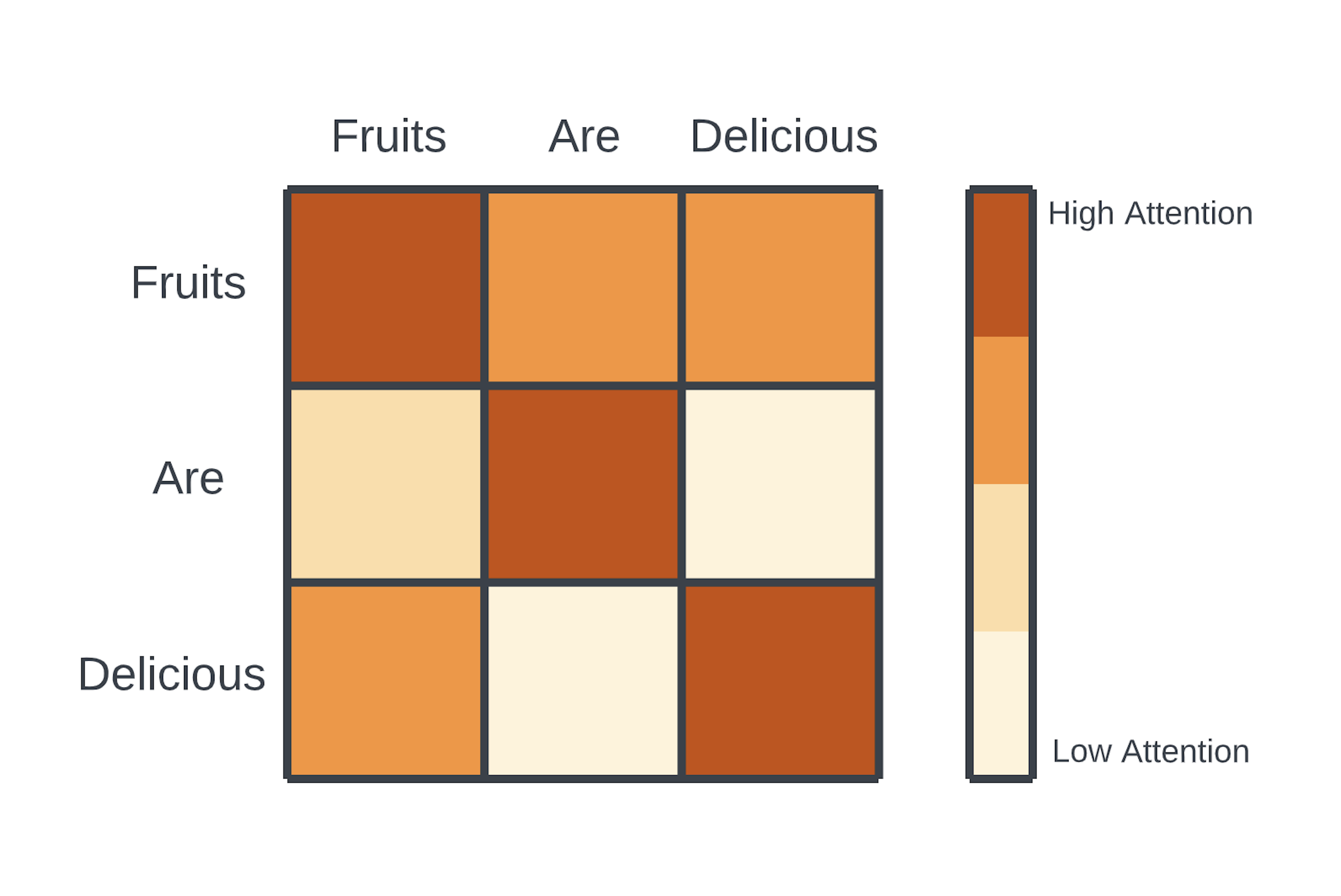
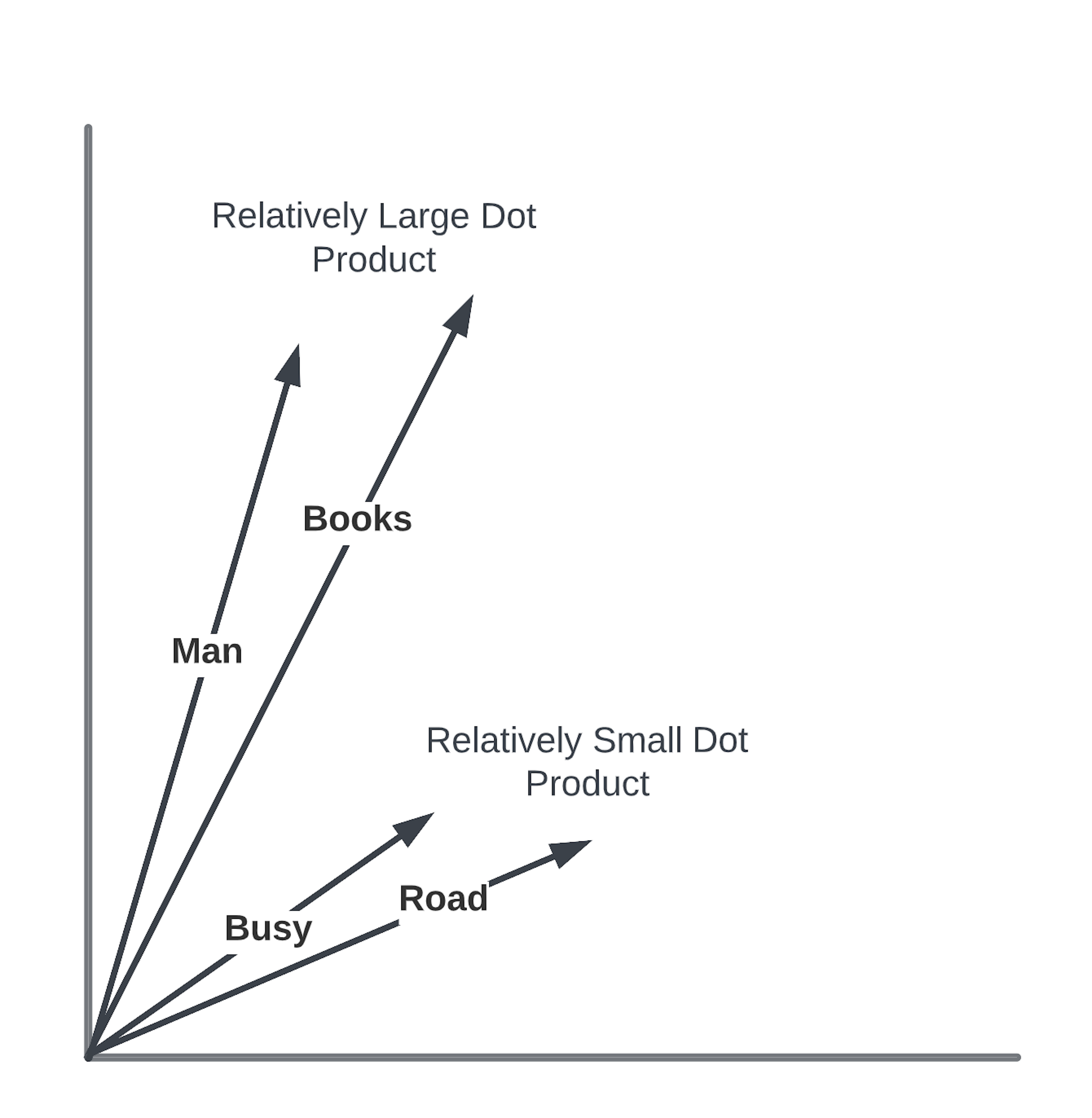
比如,有一个句子:“一个男人走在繁忙的道路上,手里拿着他刚买的几本书。”
我们想要理解这个句子中哪些词对于理解句子的整体含义是最重要的。
词向量表示 :将句子中的每个词转换成一个向量。在这个简化的例子中,我们假设每个词的向量是二维的。
选择查询词 :我们选择一个词作为“查询”(Q),比如“男人”,我们想要知道这个词在句子中与其他词的关系。
计算相似度 :将“男人”的向量与句子中其他词的向量(这里我们把它们当作“键”K)进行比较,比如“书”和“道路”。通过计算向量间的点积来评估它们之间的相似度。
应用注意力权重 :根据点积的结果,我们给每个词分配一个权重。如果“男人”和“书”的点积很高,意味着它们之间有很强的关联,因此“书”会得到一个较大的权重。
简化决策 :在这个例子中,我们简化了决策过程,认为“男人”和“书”之间的关系比“男人”和“道路”之间的关系更重要,因为“书”直接描述了“男人”的行为。
最终输出 :通过加权这些关系,我们可以得到一个综合的表示,这个表示强调了“男人”和“书”之间的关系,而对“男人”和“道路”的关系给予较少的重视。
通过这种方式,注意力机制帮助我们识别和强调句子中最重要的部分,忽略那些可能不那么关键的信息。在这个例子中,它帮助我们集中关注“男人”和“书”,因为它们对于理解句子可能更为重要。
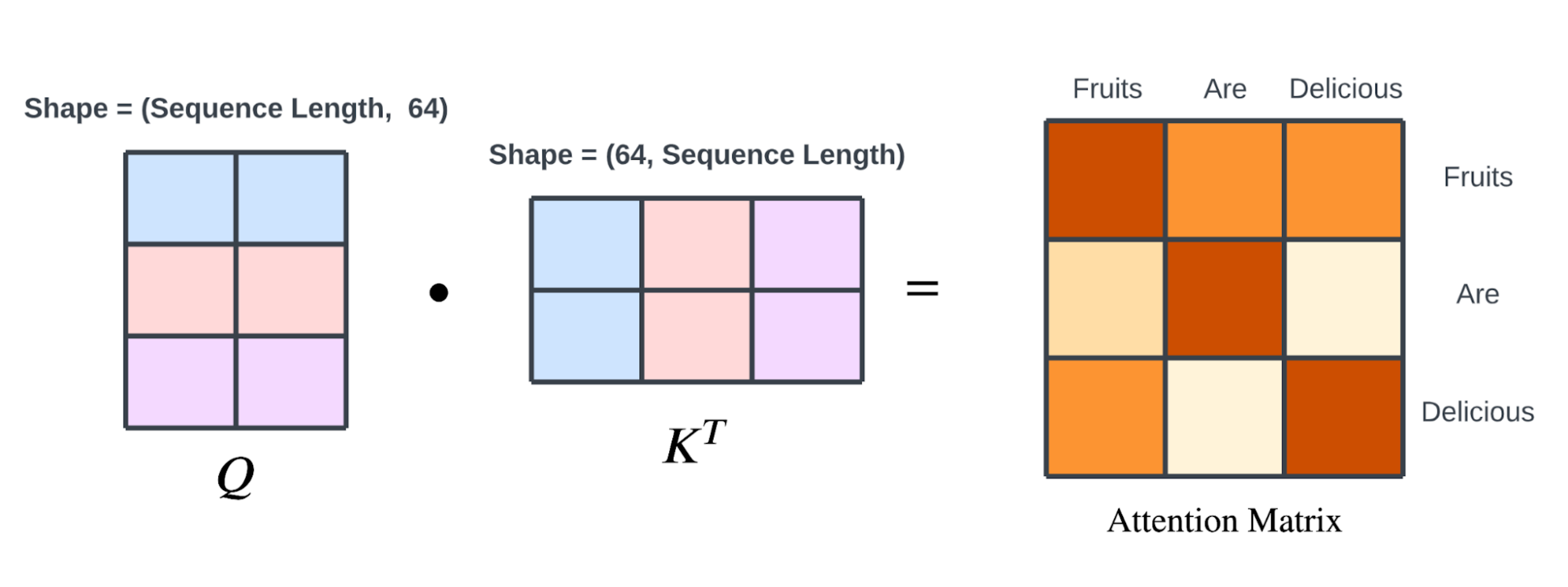
在Transformer中使用的缩放点积注意力权重计算,可以使用查询 $Q(N×D)$ 和输入$K(N×D)$ 以下的公式表示。
当处理的数据是 “用 $D$ 维词向量表示的 $N$ 个词的文章数据” 时,$Q$ 和 $K$ 是 $N×D$ 大小的矩阵。
2.7.2 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import numpy as npimport torchfrom torch import nnclass ScaledDotProductAttention (nn.Module): def __init__ (self, d_k: int ) -> None : super ().__init__() self.d_k = d_k def forward ( self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, mask: torch.Tensor = None , ) -> torch.Tensor: scalar = np.sqrt(self.d_k) attention_weight = torch.matmul(q, torch.transpose(k, 1 , 2 )) / scalar if mask is not None : if mask.dim() != attention_weight.dim(): raise ValueError( "掩码的维度与注意力权重的维度不匹配,掩码的维度={}, 注意力权重的维度={}" .format ( mask.dim(), attention_weight.dim() ) ) attention_weight = attention_weight.data.masked_fill_( mask, -torch.finfo(torch.float ).max ) attention_weight = nn.functional.softmax(attention_weight, dim=2 ) return torch.matmul(attention_weight, v)
如果掩码的维度不等于注意力权重的维度,将引发错误。
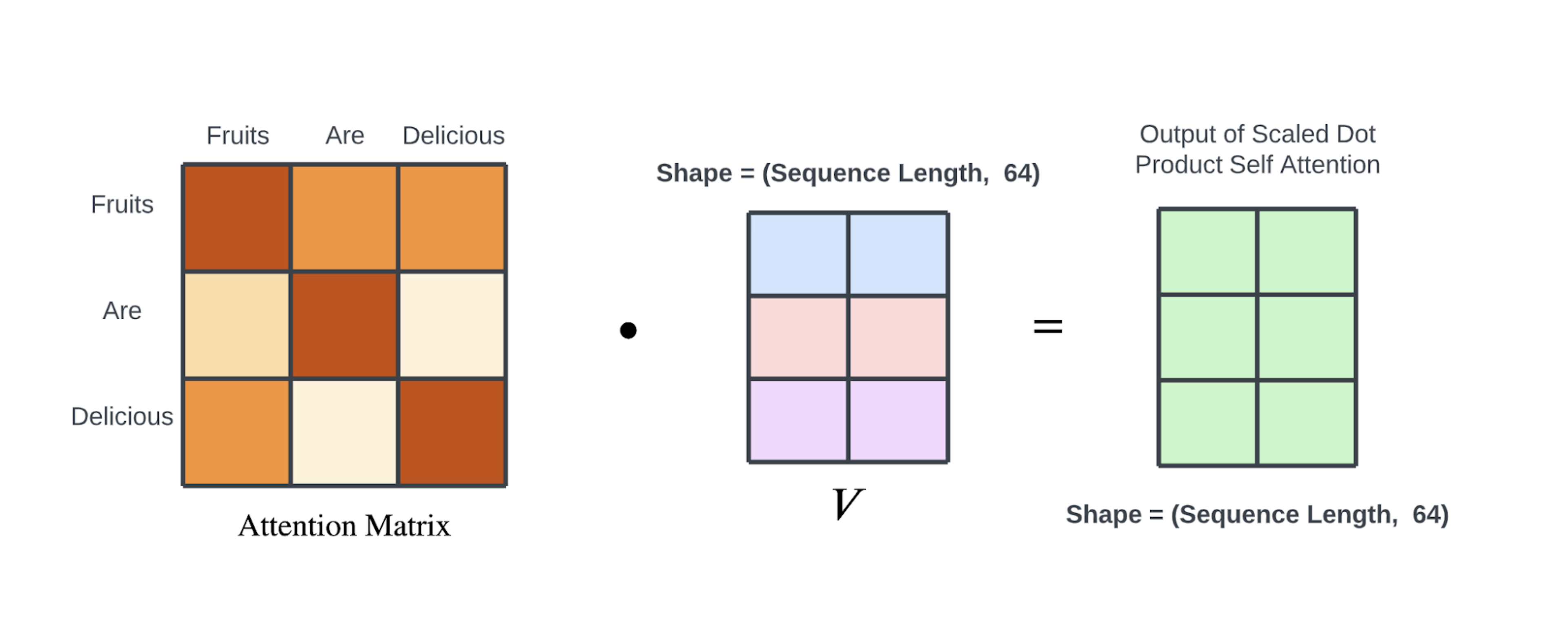
注意力权重通过softmax函数计算得出:
1 attention_weight = nn.functional.softmax(attention_weight, dim=2 )
最终,通过注意力权重和 输入X 的乘积得到加权结果:
1 return torch.matmul(attention_weight, v)
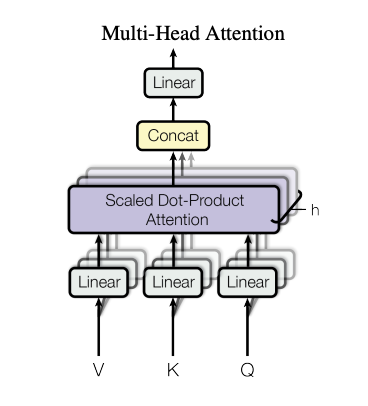
第八节 多头注意力机制 2.8.1 多头注意力机制
让我们来看一下论文中Multihead Attention的示意图。
分析多头自注意力:专用注意力头承担重任,其余部分可以修剪 》中,Elena Voita 等人提出,在 8 个注意力头中,有三个“专用”注意力头承担了大部分工作。具体来说,这些专用注意力头的作用被假设如下:
图中的 $h$(头数) 表示并行运行的 ScaledDotProductAttention 的数量。
Multihead Attention执行以下处理:
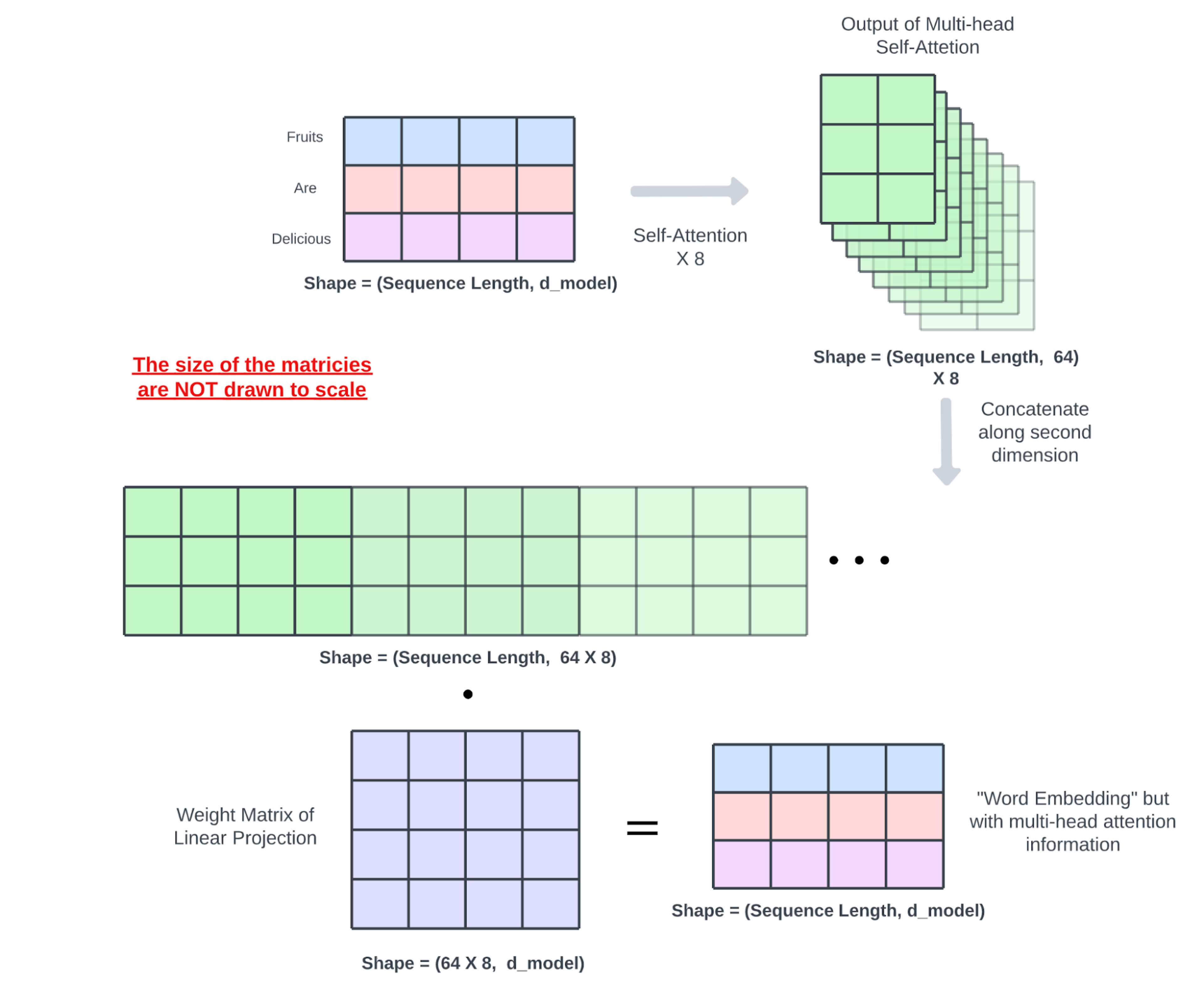
将输入$Q(N_q×d_{model})$、$K(N×d_{model})$、$V(N×d_{model})$复制成 $h$(头数)份。
使用矩阵 $W_i^q(d_{model}×d_k)$、$W_i^k(d_{model}×d_k)$、$W_i^v(d_{model}×d_v)$ 将复制的输入 $Q_i$、$K_i$、$V_i$ 分别线性变换为$d_{model}→d_v,d_k$。
将获得的 $Q_iW_i^q$、$K_iW_i^k$、$V_iW_i^v$ 输入到 $h$ 个存在的 ScaledDotProductAttention 中。
将并行运行的 ScaledDotProductAttention 得到的 $h$ 个输出头 $head(i=1 \sim h,N×d_v)$ 连接(concat)起来,得到矩阵$O(N×hd_v)$。
使用 $OW^O$ 将 $O$ 从 $hd_v$ 变换到 $d_{model}$ ,得到的值作为最终输出。
公式化表示如下:
$$
2.8.2 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 import torchfrom layers.transformer.ScaledDotProductAttention import ScaledDotProductAttentionfrom torch import nnclass MultiHeadAttention (nn.Module): def __init__ (self, d_model: int , h: int ) -> None : super ().__init__() self.d_model = d_model self.h = h self.d_k = d_model // h self.d_v = d_model // h self.W_k = nn.Parameter( torch.Tensor(h, d_model, self.d_k) ) self.W_q = nn.Parameter( torch.Tensor(h, d_model, self.d_k) ) self.W_v = nn.Parameter( torch.Tensor(h, d_model, self.d_v) ) self.scaled_dot_product_attention = ScaledDotProductAttention(self.d_k) self.linear = nn.Linear(h * self.d_v, d_model) def forward ( self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, mask_3d: torch.Tensor = None , ) -> torch.Tensor: batch_size, seq_len = q.size(0 ), q.size(1 ) q = q.repeat(self.h, 1 , 1 , 1 ) k = k.repeat(self.h, 1 , 1 , 1 ) v = v.repeat(self.h, 1 , 1 , 1 ) q = torch.einsum( "hijk,hkl->hijl" , (q, self.W_q) ) k = torch.einsum( "hijk,hkl->hijl" , (k, self.W_k) ) v = torch.einsum( "hijk,hkl->hijl" , (v, self.W_v) ) q = q.view(self.h * batch_size, seq_len, self.d_k) k = k.view(self.h * batch_size, seq_len, self.d_k) v = v.view(self.h * batch_size, seq_len, self.d_v) if mask_3d is not None : mask_3d = mask_3d.repeat(self.h, 1 , 1 ) attention_output = self.scaled_dot_product_attention( q, k, v, mask_3d ) attention_output = torch.chunk(attention_output, self.h, dim=0 ) attention_output = torch.cat(attention_output, dim=2 ) output = self.linear(attention_output) return output
第九节 位置前馈网络
Position-wise Feed-Forward Networks(FFN)的公式化表示如下:
接下来,让我们看看实现。
1 2 3 4 5 6 7 8 9 10 11 12 import torchfrom torch import nnfrom torch.nn.functional import reluclass FFN (nn.Module): def __init__ (self, d_model: int , d_ff: int ) -> None : super ().__init__() self.linear1 = nn.Linear(d_model, d_ff) self.linear2 = nn.Linear(d_ff, d_model) def forward (self, x: torch.Tensor ) -> torch.Tensor: return self.linear2(relu(self.linear1(x)))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 import torchfrom layers.transformer.TransformerDecoder import TransformerDecoderfrom layers.transformer.TransformerEncoder import TransformerEncoderfrom torch import nnclass Transformer (nn.Module): def __init__ ( self, src_vocab_size: int , tgt_vocab_size: int , max_len: int , d_model: int = 512 , heads_num: int = 8 , d_ff: int = 2048 , N: int = 6 , dropout_rate: float = 0.1 , layer_norm_eps: float = 1e-5 , pad_idx: int = 0 , device: torch.device = torch.device("cpu" ): super ().__init__() self.src_vocab_size = src_vocab_size self.tgt_vocab_size = tgt_vocab_size self.d_model = d_model self.max_len = max_len self.heads_num = heads_num self.d_ff = d_ff self.N = N self.dropout_rate = dropout_rate self.layer_norm_eps = layer_norm_eps self.pad_idx = pad_idx self.device = device self.encoder = TransformerEncoder( src_vocab_size, max_len, pad_idx, d_model, N, d_ff, heads_num, dropout_rate, layer_norm_eps, device, ) self.decoder = TransformerDecoder( tgt_vocab_size, max_len, pad_idx, d_model, N, d_ff, heads_num, dropout_rate, layer_norm_eps, device, ) self.linear = nn.Linear(d_model, tgt_vocab_size) def forward (self, src: torch.Tensor, tgt: torch.Tensor ) -> torch.Tensor: """ 参数: ---------- src : torch.Tensor 单词的ID序列,形状为[batch_size, max_len] tgt : torch.Tensor 单词的ID序列,形状为[batch_size, max_len] """ pad_mask_src = self._pad_mask(src) src = self.encoder(src, pad_mask_src) mask_self_attn = torch.logical_or( self._subsequent_mask(tgt), self._pad_mask(tgt) ) dec_output = self.decoder(tgt, src, pad_mask_src, mask_self_attn) return self.linear(dec_output) def _pad_mask (self, x: torch.Tensor ) -> torch.Tensor: """根据单词的ID序列创建padding掩码。 参数: ---------- x : torch.Tensor 单词的ID序列,形状为[batch_size, max_len] """ seq_len = x.size(1 ) mask = x.eq(self.pad_idx) mask = mask.unsqueeze(1 ) mask = mask.repeat(1 , seq_len, 1 ) return mask.to(self.device) def _subsequent_mask (self, x: torch.Tensor ) -> torch.Tensor: """为解码器的Masked-Attention创建掩码。 参数: ---------- x : torch.Tensor 单词的token序列,形状为[batch_size, max_len, d_model] """ batch_size = x.size(0 ) max_len = x.size(1 ) return ( torch.tril(torch.ones(batch_size, max_len, max_len)).eq(0 ).to(self.device) )
为了训练模型,我们在train.py中定义了一个名为Trainer的类,用于训练。
Trainer类参考了PyTorch Lightning的API,包含以下五个方法:
loss_fn: 计算损失函数
train_step: 训练中的单步(训练)
val_step: 训练中的单步(验证)
fit: 通过批量学习进行模型的训练和验证
test: 使用测试数据进行模型验证
那么我们来看看它的实现。 Trainer类的实现如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 from os.path import joinfrom typing import List , Tuple import torchfrom matplotlib import pyplot as pltfrom torch import nn, optimfrom torch.utils.data import DataLoaderfrom const.path import FIGURE_PATH, KFTT_TOK_CORPUS_PATH, NN_MODEL_PICKLES_PATH, TANAKA_CORPUS_PATHfrom models import Transformerfrom utils.dataset.Dataset import KfttDatasetfrom utils.evaluation.bleu import BleuScorefrom utils.text.text import tensor_to_text, text_to_tensorfrom utils.text.vocab import get_vocabclass Trainer : def __init__ ( self, net: nn.Module, optimizer: optim.Optimizer, criterion: nn.Module, bleu_score: BleuScore, device: torch.device, ) -> None : self.net = net.to(device) self.optimizer = optimizer self.criterion = criterion self.device = device self.bleu_score = bleu_score def loss_fn (self, preds: torch.Tensor, labels: torch.Tensor ) -> torch.Tensor: return self.criterion(preds, labels) def train_step (self, src: torch.Tensor, tgt: torch.Tensor ) -> Tuple [torch.Tensor, torch.Tensor, float ]: self.net.train() output = self.net(src, tgt) tgt = tgt[:, 1 :] output = output[:, :-1 , :] loss = self.loss_fn( output.contiguous().view(-1 , output.size(-1 )), tgt.contiguous().view(-1 ) ) _, output_ids = torch.max (output, dim=-1 ) bleu_score = self.bleu_score(tgt, output_ids) self.optimizer.zero_grad() loss.backward() self.optimizer.step() return loss, output, bleu_score def val_step (self, src: torch.Tensor, tgt: torch.Tensor ) -> Tuple [torch.Tensor, torch.Tensor, float ]: self.net.eval () output = self.net(src, tgt) tgt = tgt[:, 1 :] output = output[:, :-1 , :] loss = self.loss_fn( output.contiguous().view(-1 , output.size(-1 )), tgt.contiguous().view(-1 ) ) _, output_ids = torch.max (output, dim=-1 ) bleu_score = self.bleu_score(tgt, output_ids) return loss, output, bleu_score def fit (self, train_loader: DataLoader, val_loader: DataLoader, print_log: bool = True ): train_losses, train_bleu_scores = [], [] if print_log: print (f"{'-' *20 } Train {'-' *20 } " ) for i, (src, tgt) in enumerate (train_loader): src, tgt = src.to(self.device), tgt.to(self.device) loss, _, bleu_score = self.train_step(src, tgt) src, tgt = src.to("cpu" ), tgt.to("cpu" ) if print_log: print (f"train loss: {loss.item()} , bleu score: {bleu_score} , iter: {i+1 } /{len (train_loader)} " ) train_losses.append(loss.item()) train_bleu_scores.append(bleu_score) val_losses, val_bleu_scores = [], [] if print_log: print (f"{'-' *20 } Validation {'-' *20 } " ) for i, (src, tgt) in enumerate (val_loader): src, tgt = src.to(self.device), tgt.to(self.device) loss, _, bleu_score = self.val_step(src, tgt) src, tgt = src.to("cpu" ), tgt.to("cpu" ) if print_log: print (f"val loss: {loss.item()} , iter: {i+1 } /{len (val_loader)} " ) val_losses.append(loss.item()) val_bleu_scores.append(bleu_score) return train_losses, train_bleu_scores, val_losses, val_bleu_scores def test (self, test_data_loader: DataLoader ) -> Tuple [List [float ], List [float ]]: test_losses, test_bleu_scores = [], [] for i, (src, tgt) in enumerate (test_data_loader): src, tgt = src.to(self.device), tgt.to(self.device) loss, _, bleu_score = self.val_step(src, tgt) src, tgt = src.to("cpu" ), tgt.to("cpu" ) test_losses.append(loss.item()) test_bleu_scores.append(bleu_score) return test_losses, test_bleu_scores
现在我们来训练一下模型。运行以下命令来训练模型。
1 poetry run python train.py
第十二节 总结
第三章 实验 参考:
https://www.datacamp.com/tutorial/building-a-transformer-with-py-torch
https://github.com/YadaYuki/en_ja_translator_pytorch/tree/master
https://github.com/karpathy/nanoGPT
换源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [tool.poetry] name = "en_ja_translator_pytorch" version = "0.1.0" description = "" authors = ["YadaYuki <yada.yuki@fuji.waseda.jp>" ][[tool.poetry.source]] name = "aliyun" url = "http://mirrors.aliyun.com/pypi/simple" default = true [tool.poetry.dependencies] python = "^3.8" requests = "^2.27.1" scikit-learn = "^1.0.2" torch = "^1.10.2" pytest = "^7.0.1" matplotlib = "^3.5.1" sklearn = "^0.0" torchtext = "^0.12.0" [tool.poetry.dev-dependencies] mypy = "^0.931" isort = "^5.10.1" flake8 = "^4.0.1" black = "^22.1.0" types-requests = "^2.27.10" [build-system] requires = ["poetry-core>=1.0.0" ]build-backend = "poetry.core.masonry.api"
阅读扩展
1.1 层归一化
作用:
稳定训练过程 :
Layer Normalization通过对每个样本的特征进行归一化,使得每层的输入具有相似的分布。这有助于在训练过程中使梯度的变化更加平滑和稳定,减轻梯度爆炸或消失的问题。
加速收敛 :
归一化可以使模型的优化过程更高效,从而加速收敛。模型的参数更新更趋于稳定,训练速度更快。
减少依赖于批大小 :
与Batch Normalization不同,Layer Normalization是对单个样本的特征进行归一化,而不是对整个mini-batch进行归一化。这使得它在处理小批量数据甚至单个样本时表现更好,更加稳定。
提高模型的泛化能力 :
通过减少特征间的相互依赖性,Layer Normalization有助于提高模型在未见数据上的表现,增强模型的泛化能力。
实现:
Layer Normalization对每个样本的特征进行归一化处理,即对于一个输入向量 $ x = (x_1, x_2, \ldots, x_n) $,其归一化公式如下:
$$
其中:
$ \mu $ 是输入向量的均值:
$ \sigma $ 是输入向量的标准差:
$ \gamma $ 和 $ \beta $ 是可训练的缩放和平移参数。
1.2 残差连接的作用
1.3 前馈网络与最终编码表示 归一化后的输出会通过一个浅层三层前馈网络进行处理,该网络生成输入序列的最终编码表示。
这个前馈网络包括两个线性变换和一个 ReLU 激活函数:
第一层线性变换 :将输入映射到高维空间(通常为 2048 个神经元)。ReLU 激活函数 :引入非线性,使得模型能够捕捉到数据中的复杂关系。第二层线性变换 :将高维空间的表示映射回输入的原始维度(通常为 512 个神经元)。
前馈网络的目的是在局部进行深度特征提取,增强模型的表示能力。经过前馈网络处理后的输出,再次经过层归一化和残差连接(Add & Norm),进一步稳定了训练过程。
1.4 编码层的整体架构
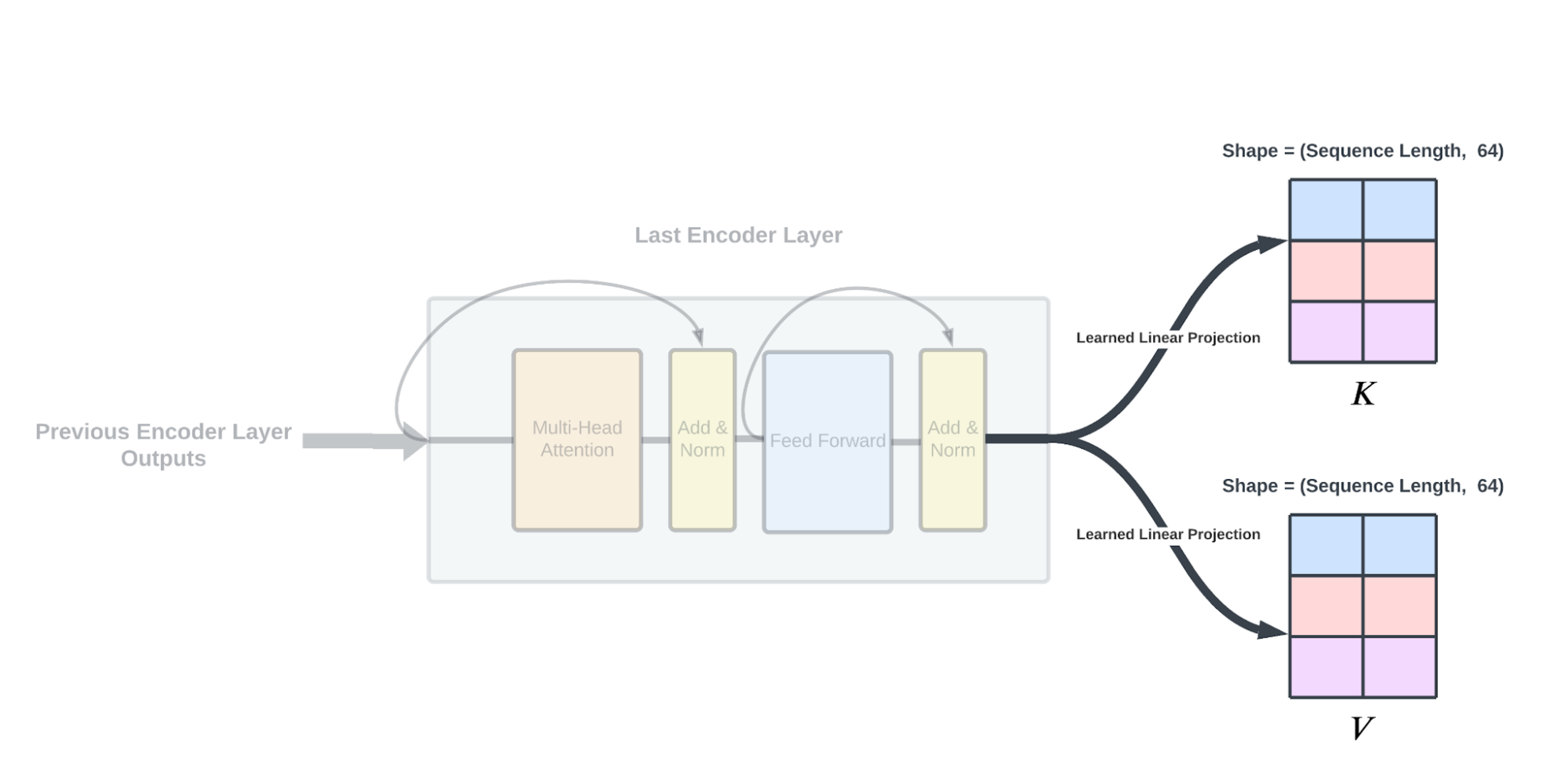
第二节 编码器输出 最后一个编码器层的输出经过另一组通过反向传播学习的线性投影,类似于在自注意力模块中执行的线性投影,从而产生一个键和一个值矩阵以输入到解码器中。
在对编码器方面进行详尽解释之后,让我们深入研究解码器。
第三节 内部协变量偏移问题的产生
在深层神经网络中,内部协变量偏移(Internal Covarian Shift)可拆成“中间”与“协变量偏移”来解读。