OpenCV 基础
第一章 OpenCV 介绍
![]()
OpenCV 全称为开源计算机视觉库(Open Source Computer Vision Library),它是一个功能强大的开源计算机视觉和机器学习软件库。最初由英特尔公司开发,如今由 OpenCV 基金会下属的开发人员社区进行维护。
OpenCV 是一个庞大的开源库,在计算机视觉、机器学习和图像处理领域有着广泛的应用。尤其在实时操作方面,它发挥着至关重要的作用,这在当今的各类系统中是非常关键的。利用 OpenCV,人们可以对图像和视频进行处理,实现物体、人脸甚至人类笔迹的识别等功能。
当与 NumPy 等其他库进行集成时,Python 可以利用 OpenCV 的数组结构进行分析。为了识别图像的模式及其各种特征,我们会运用向量空间并对这些特征进行数学运算。
OpenCV 的首个版本是 1.0。它是在 BSD 许可证下发布的,因此无论是学术研究还是商业应用,都可以免费使用。OpenCV 提供了 C++、C、Python 和 Java 等多种接口,并且支持 Windows、Linux、Mac OS、iOS 和 Android 等多种操作系统。在设计 OpenCV 时,其重点关注了实时应用程序的计算效率,所有内容均采用优化的 C/C++编写,以便充分利用多核处理的优势。
第一节 OpenCV 的应用

使用 OpenCV 解决的应用有很多,下面列出了其中一些:
- 人脸识别
- 自动化检查和监控
- 人数 – 计数(商场的人流量等)
- 高速公路上的车辆及其速度
- 互动艺术装置
- 制造过程中的异常(缺陷)检测(奇数次品)
- 街景图像拼接
- 视频/图像搜索和检索
- 机器人和无人驾驶汽车导航和控制
- 物体识别
- 医学图像分析
- 电影 – 运动的 3D 结构
- 电视频道广告识别
第二节 OpenCV 功能
一、图像/视频相关功能
- I/O:图像/视频的输入与输出。
- 处理:对图像/视频进行处理。
- 显示:包括 core(核心)、imgproc(图像处理)、highgui(高级图形用户界面)。
二、对象与特征检测
- objDetect:对象检测。
- features2d:二维特征检测。
- nonfree:非自由模块。
三、基于几何的计算机视觉
- calib3d:三维校准。
- 拼接:图像拼接。
- videostab:视频稳定。
四、计算摄影
- 照片:处理照片。
- 视频:处理视频。
- 超分辨率:提升图像分辨率。
五、机器学习与聚类
- ml:机器学习。
- flann:快速最近邻搜索库。
六、CUDA 加速(GPU)
七、图像处理的定义与作用
- 定义:图像处理是对数字化图像的分析和操作。
- 作用:为了获得增强的图像和/或从中提取有用信息,特别是为了提高图像质量。
第三节 数字图像与色彩空间
图像可以通过二维函数(f(x,y))来定义,其中(x)、(y)为空间(平面)坐标。(f)在坐标对((x,y))处的幅度被称为该点的强度或灰度级别。简单来说,图像就是一个二维矩阵(彩色图像则为三维矩阵),由任意点的数学函数(f(x,y))确定,该函数给出了相应点的像素值。在图像中,像素值体现了像素的亮度及颜色信息。
图像处理从本质上讲属于信号处理,其输入为图像,输出可以是图像本身,也可以是根据图像相关要求得出的特征。
因此计算机并非像人类那样“看”图像,而是将图像解释为数值数组。计算机读取和处理图像的基本过程如下:
- 像素值:图像由像素组成,每个像素是图像中最小的信息单位。每个像素都有代表其颜色和强度的值,对于 RGB 图像,每个像素有三个值,分别对应红色、绿色和蓝色通道。
- 数字表示:RGB 值通常用(0)到(255)之间的整数表示。(0)表示没有颜色(黑色),(255)表示该颜色的最大强度(全亮度)。
- 图像矩阵:计算机将图像读取为数字矩阵,矩阵中的每个元素对应于相应位置的像素值。对于彩色图像,通常有三个矩阵,分别对应每个 RGB 通道。
- 图像处理:运用图像处理算法对这些数字表示进行操作。常见操作包括调整大小、裁剪、过滤等。
颜色空间是用于表示图像中颜色通道存在方式的一种手段,它使图像呈现出特定的色彩倾向。目前存在多种不同的颜色空间,各自有着独特的含义。一些较为常见的色彩空间包括 RGB(红、绿、蓝)、CMYK(青、品红、黄、黑)、HSV(色调、饱和度、明度)等。
1.3.1 灰度图片
灰度图是一种只有亮度信息,没有色彩信息的图像。在灰度图像中,每个像素的颜色值又称为灰度,范围一般从 0 到 255,白色为 255,黑色为 0,灰度值是指色彩的浓淡程度。
灰度图的颜色深度通常为 8 位,具有 256 个灰度级,不同数值表示不同程度的灰色。像素值越低,灰色越深;像素值越高,灰色越浅。0 表示纯黑色,255 表示纯白色。灰度图为单通道,通常用二维数组表示一幅灰度图像。
在计算机中,灰度图可以通过将彩色图像转换为灰度图来实现,这可以作为图像处理的预处理步骤,为之后的图像分割、图像识别和图像分析等上层操作做准备。
1.3.1 BGR 色彩空间
OpenCV 的默认色彩空间是 RGB,但实际上它是以 BGR 格式来存储颜色的。BGR 是一种加色模型,蓝色、绿色和红色的不同强度组合能够产生不同的颜色层次。
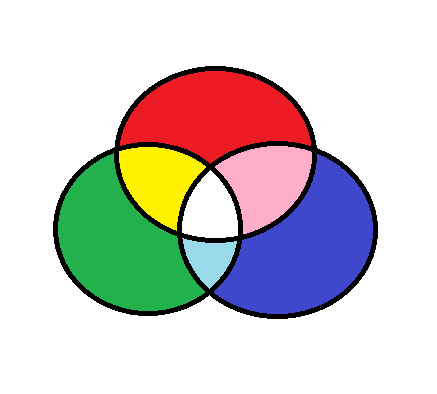
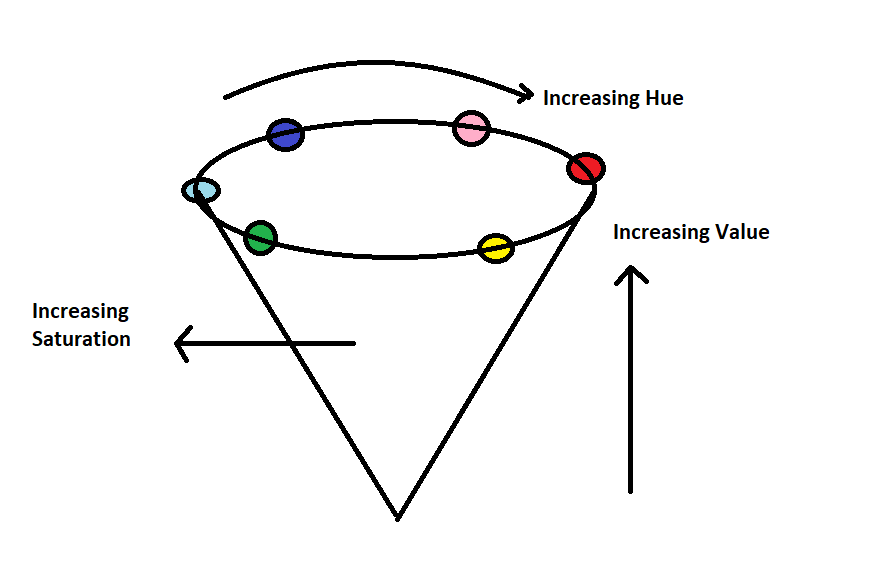
1.3.2 HSV 颜色空间
以 RGB 颜色点的圆柱表示形式来存储颜色信息的方式。它旨在模拟人眼对颜色的感知。在 HSV 颜色空间中,色调值的范围是 0 到 179,饱和度值的范围是 0 到 255,明度值的范围是 0 到 255。它主要被用于颜色分割等目的。
H:色调代表主波长。
S:饱和度代表颜色的深浅。
V:明度值代表强度。
1.3.3 CMYK 色彩空间
CMYK 色彩空间与 RGB 有着很大的区别,它属于减色色彩空间。
CMYK 模型的运作原理是通过部分或完全遮盖较浅的(通常为白色)背景上的颜色来实现的。墨水会减少原本应该反射的光。这种模型被称为减色法,这是因为墨水从白光中“减去”了红色、绿色和蓝色。当白光减去红色时,叶子会呈现出青色;当白光减去绿色时,叶子会呈现出洋红色;当白光减去蓝色时,叶子会呈现出黄色。

1.3.4 读取不同通道
1 | import cv2 |
1.3.5 色彩空间转换
cv2.cvtColor()方法用于将图像从一种颜色空间转换为另一种颜色空间。 OpenCV 中有超过 150 种颜色空间转换方法。下面我们将使用一些颜色空间转换代码。
语法: cv2.cvtColor(src, code[, dst[, dstCn]])
参数:
src:要改变色彩空间的图像。
code:颜色空间转换代码。
dst:与 src 图像大小和深度相同的输出图像。它是一个可选参数。
dstCn:目标图像的通道数。如果参数为 0,则通道数自动从 src 和代码中得出。它是一个可选参数。
return:返回一个图像。
1.3.5.1 灰度图
1 | # 导入 cv2 |
1.3.5.2 YCrCb 色彩空间
Y 代表亮度或亮度分量,Cb 和 Cr 是色度分量。 Cb 表示蓝色差(蓝色分量与亮度分量的差)。 Cr 表示红差(红色分量与亮度分量的差)。
YUV 和 YCbCr 是两种类似的颜色编码格式,它们之间存在以下关系:
- YUV 是一种颜色编码格式,其中 Y 表示亮度,U 和 V 表示色度。YUV 常用于视频和图像处理中,将亮度和色度信息分开处理。
- YCbCr 是 YUV 的一种变体,其中 Y 仍然表示亮度,Cb 和 Cr 表示色度。YCbCr 是在 YUV 的基础上进行了一些调整和变换。
- 在实际应用中,YUV 和 YCbCr 的具体实现可能会有所不同,但它们的基本原理是相似的。一些视频和图像处理标准可能会使用特定的 YUV 或 YCbCr 格式。
- 对于大多数应用来说,可以将 YUV 和 YCbCr 视为类似的概念,但在具体的处理和使用中,需要根据所采用的标准和设备来确定使用哪种格式。
1 | # 导入 cv2 模块 |
1.3.5.3 HSV 色彩空间
在颜色模式中,HSV 是指色调(Hue)、饱和度(Saturation)、明度(Value)。
色调表示颜色的种类,如红色、蓝色等;饱和度表示颜色的纯度,饱和度越高颜色越鲜艳,饱和度为 0 时则为灰色;明度表示颜色的明亮程度,从黑到白变化。
这种颜色模式在图像处理、计算机图形学等领域有广泛应用。
1 | # 导入 cv2 模块 |
1.3.5.4 实验室色彩空间
L——代表轻盈。
A –颜色成分,范围从绿色到洋红色。
B –颜色分量,范围从蓝色到黄色。
1 | # 导入 cv2 模块 |
第二章 OpenCV 基础使用
第一节 安装
在命令行下安装:
1 | pip install opencv-contrib-python |
查看 cv2 版本:
1 | import cv2 |
第二节 基础使用
为了了解 Python OpenCV 模块的基本功能,我们将先从简单直接的例子来介绍 OpenCV 最基本的概念。
2.2.1 OpenCV 库支持的文件类型
- Windows 位图:_.bmp、_.dib
- JPEG 文件:_.jpeg、_.jpg
- 便携式网络图形:*.png
- WebP:*.webp
- 太阳光栅:_.sr、_.ras
- TIFF 文件:_.tiff、_.tif
- GDAL 支持的栅格和矢量地理空间数据
2.2.2 读取图像
一般过程:
- 使用 imread()函数读取图像。
- 创建 GUI 窗口并使用 imshow()函数显示图像。
- 使用 waitkey(0)函数将图像窗口在屏幕上保持指定的秒数,0 表示直到用户关闭它为止。
- 显示后使用 destroyAllWindows()函数从内存中删除图像窗口。
首先,我们将导入 cv2 模块,然后使用 cv2 的 imread() 方法读取输入图像。然后提取图像的高度和宽度。
1 | # 导入 OpenCV 库 |
2.2.3 提取像素的 RGB 值
现在我们将重点关注提取单个像素的 RGB 值。 OpenCV 按 BGR 顺序排列通道。因此第 0 个值将对应于蓝色像素而不是红色像素。
1 | # 提取 RGB 值。 |
2.2.4 提取感兴趣区域 (ROI)
有时我们想要提取图像的特定部分或区域。这可以通过分割图像的像素来完成。
1 | # 我们将通过对图像的像素进行切片来计算感兴趣区域 |
2.2.5 调整图像大小
图像的尺寸调整其实就是对图像进行缩放操作。这在众多的图像处理以及机器学习的应用场景里都极为关键。它能够削减图像里的像素数量,存在诸多益处,例如它可以缩短神经网络的训练时长,因为图像中的像素数量愈多,输入节点就会相应增多,进而加大神经网络训练的复杂性。
同时,它对图像的放大也有帮助。在很多情况下,我们都需要对图像的尺寸进行调整,也就是让图像缩小或者放大以契合特定的尺寸要求。OpenCV 给我们提供了一些用于调整图像尺寸的插值方式。
用于调整尺寸的插值方法选择:
cv2.INTER_AREA:当需要将图像缩小时使用。cv2.INTER_CUBIC:速度较慢但效果更优。cv2.INTER_LINEAR:主要在需要进行缩放操作时采用,它也是 OpenCV 中默认的插值技术。
语法:cv2.resize(source, dsize, dest, fx, fy, interpolation)
参数说明:
source:输入的图像数组(可以是单通道、8 位或者浮点型)。dsize:输出数组的尺寸大小。dest:输出数组(和输入图像数组的维度与类型相似)[可选项]。fx:沿水平轴的比例因子[可选项]。fy:沿垂直轴的比例因子[可选项]。interpolation:上述的插值方法之一[可选项]。
我们可以使用 cv2 模块的 resize() 函数在 Python 中调整图像大小,并传递输入图像并调整像素值大小。
1 | # resize() 函数有两个参数, |
这种方法的问题是无法保持图像的纵横比。所以我们需要做一些额外的工作来保持适当的纵横比。
1 | # 计算比例 |
1 | import cv2 # 导入 OpenCV 库 |
2.2.6 旋转图像
在 OpenCV 中,可以使用cv2.getRotationMatrix2D函数和cv2.warpAffine函数来旋转图像
1 | import cv2 |
2.2.7 平移图像
平移图像意味着在给定的参考系内(可以沿 x 轴和 y 轴)移动图像。
- 要使用 OpenCV 转换图像,我们需要创建一个变换矩阵。该矩阵是一个 2×3 矩阵,指定每个方向上的平移量。
- 该函数用于将变换矩阵应用于图像。它需要以下参数:cv2.warpAffine()
- The image to be transformed.
- The transformation matrix.
- The output image size.
- 平移参数在变换矩阵中指定为 tx 和 ty 元素。该 tx 元素指定 x 轴上的平移量,而该 ty 元素指定 y 轴上的平移量。
1 | # 导入必要的库 |
2.2.8 图像裁剪
图像剪切是一种几何变换,它使图像沿一个或两个轴(即 x 轴或 y 轴)倾斜。
要使用 OpenCV 剪切图像,我们需要创建一个变换矩阵。该矩阵是一个 2×3 矩阵,指定每个方向上的剪切量。
该函数用于将变换矩阵应用于图像。它需要以下参数:cv2.warpAffine()
The image to be transformed.
The transformation matrix.
The output image size.
剪切参数在变换矩阵中指定为元素。该元素指定 x 轴上的剪切量,而该元素指定 y 轴上的剪切量。
1 | import cv2 |
2.2.9 绘制一个矩形
我们可以使用 rectangle()方法在图像上绘制一个矩形。它接受 5 个参数:
- Image
- Top-left corner co-ordinates
- Bottom-right corner co-ordinates
- Color (in BGR format)
- Line width
1 | # 复制原始图像 |
2.2.10 显示文本
它也是一个可以使用 OpenCV 模块的 putText()方法完成的就地操作。它接受 7 个参数:
- Image
- Text to be displayed
- Bottom-left corner co-ordinates, from where the text should start
- Font
- Font size
- Color (BGR format)
- Line width
1 | # 复制原图 |
显示中文:
1 | from PIL import Image, ImageDraw, ImageFont |
第三章 OpenCV 进阶
第一节 OpenCV 图像显示与保存
3.1.1 图像显示
cv2.imshow() 方法用于在窗口中显示图像。窗口自动适应图像尺寸。
语法: cv2.imshow(window_name, image)
参数:
window_name:表示要在其中显示图像的窗口的名称的字符串。
image:就是要显示的图像。
3.1.1.1 显示图像
1 | # 导入 cv2 库 |
3.1.1.2 显示图片并加上窗口名称
1 | # 导入 cv2 库 |
3.1.1.3 结合 matplotlib 库
1 | import cv2 |
3.1.1.4 将 BGR 转换为 RGB
1 | import cv2 |
3.1.1.5 读取灰度图像
1 | import cv2 |
3.1.1.6 使用 shape 属性查看图像形状
可以使用 shape 属性查看图像的宽度、高度和通道数,对于灰度图像只有宽度和高度。
1 | img.shape |
3.1.2 图像保存
cv2.imwrite()方法用于将图像保存到任何存储设备。这将按照指定的格式将图像保存在当前工作目录中。
语法: cv2.imwrite(文件名, 图像)
参数:
filename:表示文件名的字符串。文件名必须包含图像格式,如**.jpg、.png**等。
image:即要保存的图像。
3.1.2.1 示例
1 | # 导入 cv2 库 |
第二节 OpenCV 图像进行算术运算
加法、减法以及位运算(如 AND、OR、NOT、XOR 等)之类的算术运算能够被运用于输入图像。这些运算有利于强化输入图像的属性。图像算法在分析输入图像的属性方面起着至关重要的作用。经过操作后的图像能够进一步当作被增强后的输入图像,并且还可以施加更多诸如澄清、阈值化、膨胀等操作于图像之上。
3.2.1 图像加法运算
我们可以使用函数**cv2.add()**添加两个图像。这直接将两个图像中的图像像素相加。
但添加像素并不是理想的情况。因此,我们使用 cv2.addweighted()。请记住,两个图像的大小和深度应相同。
语法:cv2.addWeighted(img1, wt1, img2, wt2, gammaValue)
参数:
img1:第一个输入图像数组(单通道、8 位或浮点)
wt1:要应用的第一个输入图像元素的权重最终图像
img2:第二个输入图像数组(单通道,8 位或浮点)
wt2:应用于最终图像的第二个输入图像元素的权重
gammaValue:光的测量
1 | # 整理导入项 |
3.2.2 图像减法运算
就像加法一样,我们可以使用 cv2.subtract() 减去两个图像中的像素值并合并它们。图像的大小和深度应相同。
语法: cv2.subtract(src1, src2)
1 | # 整理导入项 |
第三节 OpenCV 图像位运算
经过第二节的学习,相信大家能对图像的算术运算有一定了解。接下来,将介绍位运算,位运算用于图像处理,用于提取图像中的重要部分。
在本文中,使用的按位运算是: AND、OR、XOR、NOT
此外,按位运算有助于图像屏蔽。可以借助这些操作来创建图像。这些操作有助于增强输入图像的属性。
注意:按位运算应应用于相同尺寸的输入图像
3.3.1 两图像按位 AND 与 运算
语法: cv2.bitwise_and(source1,source2,destination,mask)
参数:
source1:第一个输入图像数组(单通道、8 位或浮点)
source2:第二个输入图像数组(单通道、8 位或浮点) float-point)
dest:输出数组(与输入图像数组的维度和类型类似)
mask:操作掩码,输入/输出 8 位单通道掩码
输入图像 1:

输入图像 2:

1 | # 整理导入项 |
3.3.2 两图像按位 OR 或 运算
输入数组元素的按位或取。
语法: cv2.bitwise_or(source1,source2,destination,mask)
参数:
source1:第一个输入图像数组(单通道、8 位或浮点)
source2:第二个输入图像数组(单通道、8 位或浮点) float-point)
dest:输出数组(与输入图像数组的维度和类型类似)
mask:操作掩码,输入/输出 8 位单通道掩码
1 | # 整理导入项 |
3.3.3 两图像按位 XOR 异或 运算
对输入数组元素进行按位异或运算。
语法: cv2.bitwise_xor(source1,source2,destination,mask)
参数:
source1:第一个输入图像数组(单通道、8 位或浮点)
source2:第二个输入图像数组(单通道、8 位或浮点) float-point)
dest:输出数组(与输入图像数组的维度和类型类似)
mask:操作掩码,输入/输出 8 位单通道掩码
1 | # 整理导入项 |
3.3.4 图像进行按位 NOT 运算
输入数组元素的反转。
语法: cv2.bitwise_not(source, destination, mask)
参数:
source:输入图像数组(单通道、8 位或浮点)
dest:输出数组(与输入图像数组的维度和类型类似)
mask:操作掩码,输入/输出 8 位单通道掩码
1 | # 整理导入项 |
第四节 形态图像处理
形态图像处理是一组基于图像中对象的几何形状的 Python 图像处理技术。这些过程通常用于消除噪声、分离对象和检测图像中的边缘。
两种最常见的形态学操作是:
- 膨胀:此操作扩大图像中对象的边界。
- 侵蚀:此操作缩小图像中对象的边界。
形态学过程通常与其他图像处理方法(例如分割和边缘检测)结合使用。
3.4.1 OpenCV 图片腐蚀
cv2.erode()方法用于对图像进行腐蚀。侵蚀的基本思想就像土壤侵蚀一样,它侵蚀前景物体的边界(始终尝试保持前景为白色)。它通常在二值图像上执行。它需要两个输入,一个是我们的原始图像,第二个称为结构元素或内核,它决定操作的性质。原始图像中的一个像素(无论是 1 还是 0)只有当核下的所有像素都为 1 时才会被认为是 1,否则它会被侵蚀(变成 0)。
腐蚀操作和膨胀操作相反,也就是将毛刺消除,判断方法为:在卷积核大小中对图片进行卷积。取图像中$3 * 3$区域内的最小值。如果是二值图像,就是取$0$(黑色)。 总结: 只要原图片$3 * 3$范围内有黑的,该像素点就是黑的。
语法: cv2.erode(src, kernel[, dst[,anchor[, iterations[, borderType[, borderValue]]]]])
参数:
src:要腐蚀的图像。
kernel:用于侵蚀的结构元素。如果 element = Mat(),则使用 3 x 3 矩形结构元素。可以使用[getStructuringElement]创建内核。
dst:是与 src 相同大小和类型的输出图像。
anchor:它是一个整数类型的变量,代表锚点,它的默认值 Point 是(-1,-1),这意味着锚点位于内核中心。
borderType:描述要添加什么样的边框。它由cv2.BORDER_CONSTANT、cv2.BORDER_REFLECT等标志定义。
iterations:它是应用侵蚀的次数。
borderValue:边界恒定时的边界值。
return:返回一个图像。
3.4.1.1 示例 1
1 | # 导入 cv2 库 |
3.4.1.2 示例 2
1 | # 导入 cv2 库 |
3.4.2 OpenCV 膨胀
膨胀是一种图像处理操作,用于增加图像中目标的大小或填充图像中的空洞。在 OpenCV 中,可以使用 cv2.dilate()函数来执行图像膨胀操作。
更通俗的说法:假设现有$33$的矩阵,kernel(卷积核核)指定为全为 1 的$33$矩阵,卷积计算后,该像素点的值等于以该像素点为中心的$3*3$范围内的最大值。如果是二值图像,只要包含周围白的部分,就变为白的。
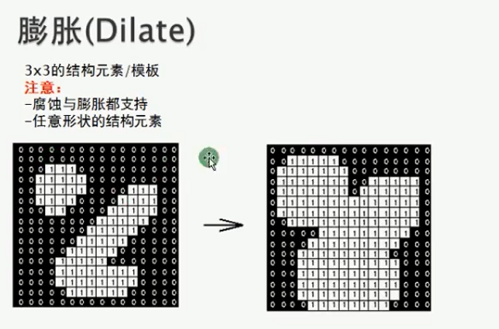
3.4.3 示例
1 | import cv2 |
第五节 OpenCV 图像模糊
图像模糊是指使图像变得不太清晰或明显。这是在各种低通滤波器内核的帮助下完成的。
高斯模糊的原理:
所谓”模糊”,可以理解成每一个像素都取周边像素的平均值。
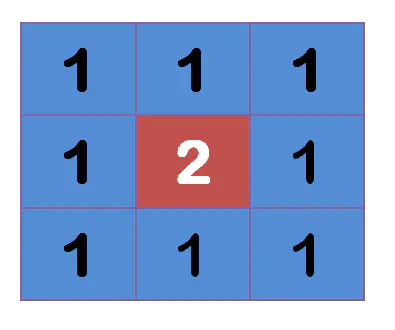
上图中,2 是中间点,周边点都是 1。
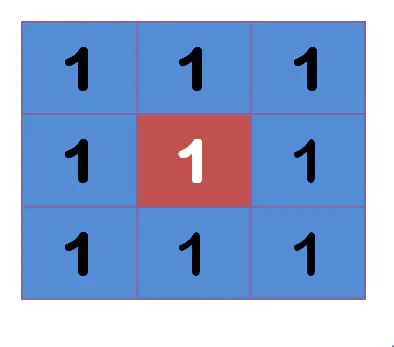
“中间点”取”周围点”的平均值,就会变成 1。在数值上,这是一种”平滑化”。在图形上,就相当于产生”模糊”效果,”中间点”失去细节。显然,计算平均值时,取值范围越大,”模糊效果”越强烈。

上面分别是原图、模糊半径 3 像素、模糊半径 10 像素的效果。模糊半径越大,图像就越模糊。从数值角度看,就是数值越平滑。那么,每个点都要取周边像素的平均值,该如何分配权重是个问题.
图像都是连续的,越靠近的点关系越密切,越远离的点关系越疏远
遵循以上原则,加权平均则更加稳妥.
距离越近的点权重越大,距离越远的点权重越小
此时,正太分布就起作用了.
三维高斯分布就是下面这样的:
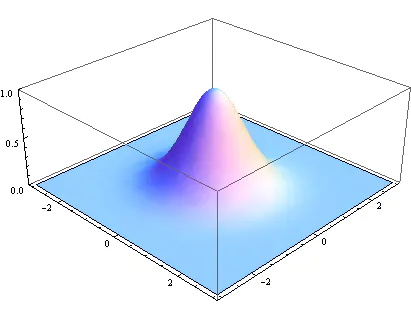
其函数表达式如下:
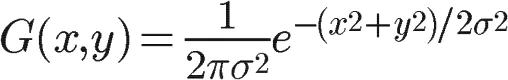
有了这个函数 ,就可以计算每个点的权重了。
计算权重矩阵
演算图示如下:
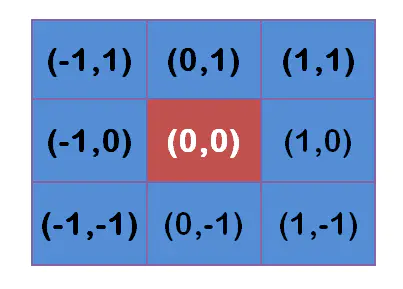
假定 σ=1.5
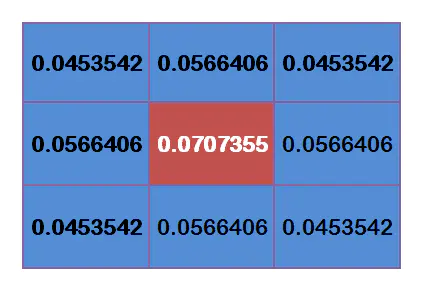
归一化,得到最终的权重矩阵:
计算高斯模糊
假设现有 9 个像素点,灰度值(0-255)如下:
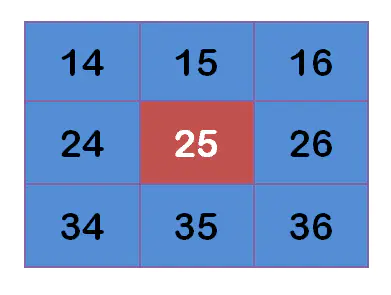
每个点乘以自己的权重值:

得到:
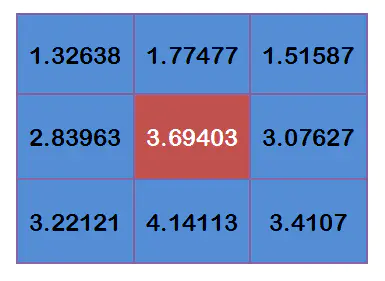
将这 9 个值加起来,就是中心点的高斯模糊的值。
对所有点重复这个过程,就得到了高斯模糊后的图像。如果原图是彩色图片,可以对 RGB 三个通道分别做高斯模糊。
边界点怎么处理?
如果一个点处于边界,周边没有足够的点,怎么办?
一个变通方法,就是把已有的点拷贝到另一面的对应位置,模拟出完整的矩阵。
3.5.1 高斯模糊
高斯模糊是通过高斯函数模糊图像的结果。它是图形软件中广泛使用的效果,通常用于减少图像噪声并减少细节。它还用作应用我们的机器学习或深度学习模型之前的预处理阶段。例如高斯核(3×3)
$$ \frac{1}{16}\cdot \begin{pmatrix} 1 & 2 & 1 \\ 2 & 4 & 2 \\ 1 & 2 & 1 \end{pmatrix} $$ 使用 1/16 作为系数主要是为了实现归一化。
具体来说,计算这个矩阵中所有元素的和为 16(1+2+1+2+4+2+1+2+1=16),将其归一化就是 1/16。这样做的目的是使得在进行卷积运算时,能保证处理后的结果在合理的范围内,不会因为矩阵元素本身的数值大小而过度影响最终的效果,确保对图像的模糊处理是适度且相对均衡的,保持图像整体特征的相对稳定和自然过渡。
1 | # 导入库 |
3.5.2 中值模糊
中值滤波器是一种非线性数字滤波技术,通常用于消除图像或信号中的噪声。中值滤波在数字图像处理中应用非常广泛,因为在某些条件下,它可以在去除噪声的同时保留边缘。它是消除椒盐噪声的最佳算法之一。
1 | # 导入库 |
3.5.3 双边模糊
双边滤波器是一种非线性、边缘保留和降噪的图像平滑滤波器。它将每个像素的强度替换为附近像素的强度值的加权平均值。该权重可以基于高斯分布。因此,保留了锋利的边缘,同时丢弃了较弱的边缘。
双边滤波的公式可以表示为:
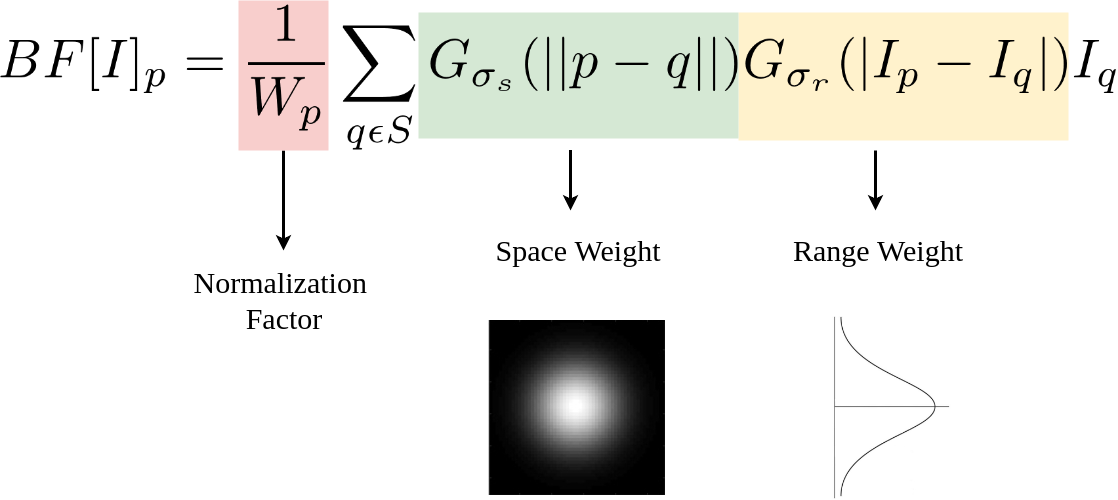
其中:
- $I_{bf}(p)$ 是滤波后像素 $p$ 的值。
- $W_p$ 是归一化因子,等于 $\sum_{q \in S} G_s(|p-q|) G_r(|I(p)-I(q)|)$。
- $G_s$ 是空间距离的高斯函数,与空间距离相关。
- $G_r$ 是像素值差异的高斯函数,与像素值差异相关。
- $S$ 是邻域。
- $I(p)$ 和 $I(q)$ 分别是像素 $p$ 和 $q$ 的值。
方法: bilateralFilter(src, dst, d, sigmaColor, sigmaSpace, borderType)
参数:
src: 表示此操作的源(输入图像)的 Mat 对象。
dst: 表示此操作的目标(输出图像)的 Mat 对象。
d: 表示像素邻域直径的整数类型变量。
sigmaColor: 表示颜色空间中的过滤器 sigma 的整数类型变量。
sigmaSpace: 表示坐标空间中的过滤器 sigma 的整数类型变量。
borderType: 表示所用边框类型的整数对象。
1 | # 导入库 |
第六节 OpenCV 创建图片框
cv2.copyMakeBorder() 方法用于在图像周围创建一个边框,如相框。
语法: cv2.copyMakeBorder(src, top, bottom, left, right, borderType, value)
参数:
src:源图像。
top:顶部方向的边框宽度(以像素数表示)。
bottom:底部方向的边框宽度(以像素数表示)。
left:左方向的边框宽度(以像素数表示)。
right:它是右方向的边框宽度(以像素数为单位)。
borderType:描述要添加什么样的边框。它由cv2.BORDER_CONSTANT、cv2.BORDER_REFLECT等标志定义dest:它是目标图像
value:它是一个可选参数,如果边框类型为cv2.BORDER_CONSTANT,则描述边框的颜色。
return:返回一个图像。
borderType 标志描述如下:
cv2.BORDER_CONSTANT:它添加恒定的彩色边框。该值应作为关键字参数给出
cv2.BORDER_REFLECT:边框将是边框元素的镜面反射。假设,如果图像包含字母“ abcdefg ”,则输出将为“ gfedcba|abcdefg|gfedcba ”。
cv2.BORDER_REFLECT_101或cv2.BORDER_DEFAULT:它的作用与cv2.BORDER_REFLECT相同,但略有变化。假设,如果图像包含字母“ abcdefgh ”,则输出将为“ gfedcb|abcdefgh|gfedcba ”。
cv2.BORDER_REPLICATE:它复制最后一个元素。假设,如果图像包含字母“ abcdefgh ”,则输出将为“ aaaaa|abcdefgh|hhhhh ”。
3.6.1 示例 1
1 | # 导入 cv2 库 |
3.6.2 示例 2
1 | # 导入 cv2 库 |
第七节 OpenCV 图像灰度化
灰度是将图像从其他颜色空间(例如 RGB、CMYK、HSV 等)转换为灰度的过程。它在全黑和全白之间变化。
灰度的重要性:
- 降维:例如,RGB 图像具有三个颜色通道和三个维度,而灰度图像是一维的。
- 降低模型复杂性:考虑在 10x10x3 像素的 RGB 图像上训练神经文章。输入层将有 300 个输入节点。另一方面,对于灰度图像,相同的神经网络只需要 100 个输入节点。
- 对于其他算法的工作:许多算法被定制为仅适用于灰度图像,例如 OpenCV 库中预先实现的 Canny 边缘检测功能仅适用于灰度图像。
3.7.1 方法 1:使用 cv2.cvtColor()函数
1 | # 导入 OpenCV |
3.7.2 方法 2:使用 cv2.imread()函数且 flag=0
1 | # 导入 OpenCV |
3.7.3 方法 3:使用像素操作(平均法)
1 | # 导入 OpenCV |
第八节 OpenCV 边缘检测
图像边缘检测主要在于探测图像里的锐利边缘。在图像识别以及对象定位或检测等情境中,这种边缘检测极为关键。鉴于其广泛的应用范畴,存在众多用于进行边缘检测的算法。
于图像处理和计算机视觉领域的应用而言,Canny 边缘检测是备受青睐的一种边缘检测手段。要实现边缘检测,Canny 边缘检测器先是对图像进行平滑操作以降低噪声,接着计算其梯度,随后对梯度实施阈值处理。
多阶段的 Canny 边缘检测流程涵盖了如下步骤:
- 高斯平滑:借助高斯滤波器来使图像平滑,进而除掉噪声。
- 梯度计算:运用 Sobel 算子来计算图像的梯度。
- 非极大值抑制:针对梯度图像执行非极大值抑制,以剔除虚假边缘。
- 滞后阈值:在梯度图像上应用滞后阈值,用以辨别强边缘和弱边缘。
Canny 边缘检测器作为一种有力的边缘检测算法,能够生成高品质的边缘图像,不过其计算开销或许也比较大。
1 | import cv2 |
第九节 OpenCV 图像标准化
图像归一化指的是把图像里的像素值缩放至特定范围的一个过程。这样做主要是为了提升图像处理算法的性能,毕竟诸多算法在像素值处于特定范围内时表现更优。
在 OpenCV 里,cv2.normalize()函数可用于图像的标准化。此函数包含如下参数:输入图像、输出图像、归一化图像的最小值和最大值、归一化类型以及输出图像的数据类型。其中,标准化类型明确了像素值的缩放方式,存在多种不同的标准化类型可供选择,每种类型在准确性与速度方面都有着自身的权衡。
图像归一化是众多图像处理任务中常见的预处理步骤,它能够助力提升图像分类、目标检测以及图像分割等算法的性能。
1 | # 导入必要的库 |
第十节 使用直方图分析图像
讨论使用 Matplotlib 和 OpenCV 进行图像分析。我们首先了解如何实验各种风格的图像数据以及如何用直方图表示。
1 | !pip install matplotlib |
因为 matplotlib 仅支持 PNG 图像。在此,本示例中使用的是 24 位 RGB 的 PNG 图像(R、G、B 各 8 位)。每个内部列表代表一个像素。这里,对于 RGB 图像,有 3 个值。对于 RGB 图像,matplotlib 支持 float32 和 uint8 数据类型。
1 | # 导入 matplotlib |
在 Matplotlib 中,这是使用**imshow()**函数执行显示图像。
3.10.1 什么是直方图
直方图是与灰度图像中像素值(0 到 255)的像素频率相关的图形或图。灰度图像每个像素值为单个样本,仅携带 0 到 255 变化的强度信息,也被称为黑白图像,由灰色阴影组成,从最弱黑色到最强白色,像素即图像中的每个点。
其外观是量化每个强度值对应的像素数。在看直方图前,从给定示例可大致了解图像的对比度、亮度、强度分布等,且所看到的图像及其直方图是针对灰度图像而非彩色图像绘制的,直方图左侧区域显示较暗像素数量,右侧区域显示较亮像素数量。
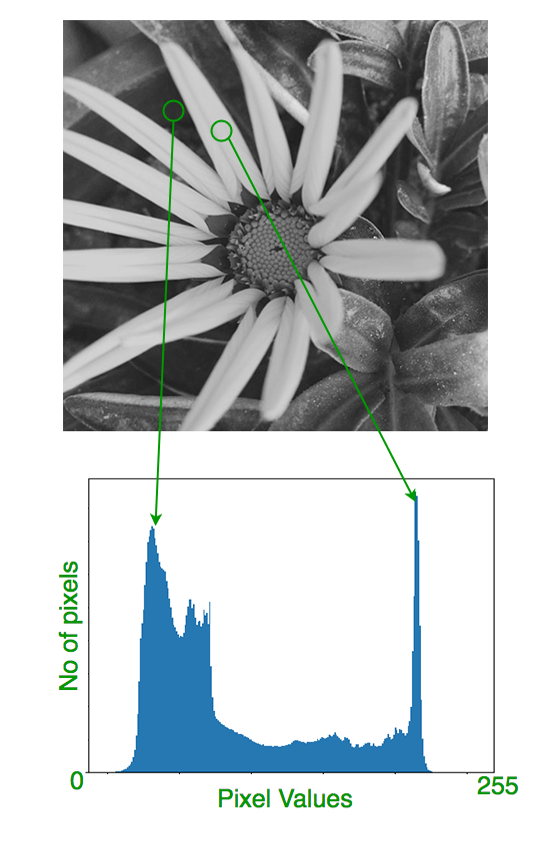
3.10.2 使用 numpy 数组创建直方图
为了创建图像数据的直方图,我们使用 hist() 函数。
1 | # 计算直方图 |
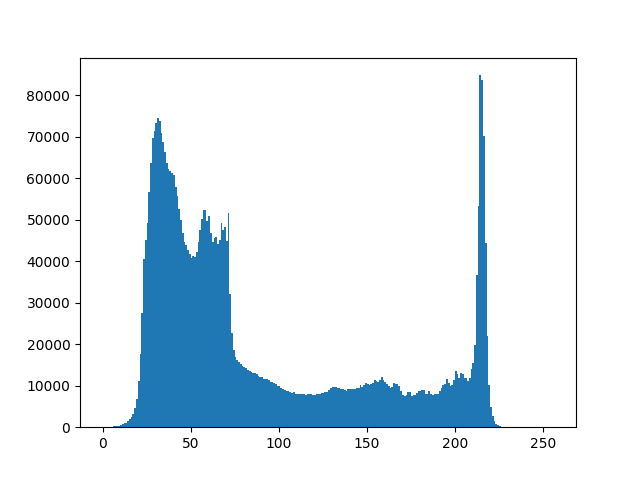
在我们的直方图中,看起来像灰度图像一样,整个图像黑白像素都有强度分布。从直方图中,我们可以得出结论,暗区域多于亮区域。
现在,我们将处理由像素值变化的像素强度分布组成的图像。首先,我们需要使用 OpenCV 内置函数计算直方图。
3.10.3 直方图计算
在这里,我们使用 cv2.calcHist()(OpenCV 中的内置函数)来查找直方图。
语法:cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])
参数:
images :它是 uint8 或 float32 类型的源图像,表示为“[img]”。
channels:它是我们计算直方图的通道索引。对于灰度图像,其值为[0],对于彩色图像,可以通过[0]、[1]或[2]分别计算蓝色、绿色或红色通道的直方图。
mask:遮罩图像。为了找到完整图像的直方图,它被指定为“None”。
histSize:这代表我们的 BIN 计数。对于全尺寸,我们通过[256]。
ranges:这是我们的范围。通常,它是[0, 256]。
1 | # 以灰度模式加载一张图像 |
然后,我们需要绘制直方图来显示图像的特征。
3.10.4 直方图绘制
3.10.4.1 示例 1
在这段代码中:
x 轴:表示像素值,范围是从 0 到 255。
y 轴:表示对应像素值出现的频率(即具有该像素值的像素数量)。
1 | # 导入 OpenCV 所需的库 |
3.10.4.1 示例 2
还有一种可以直接找到直方图并绘制。而不需要使用 calcHist()的方法。
1 | import cv2 |
第十一节 OpenCV 直方图均衡化
直方图均衡是图像处理中利用图像直方图来进行对比度调整的方法。该方法常能提升许多图像的全局对比度,尤其在图像可用数据由相近对比度值表示时,经此调整,强度能在直方图上更好分布,使局部对比度低的区域获得更高对比度,它通过有效分散最频繁的强度值来达成目的,此方法对背景和前景均亮或均暗的图像很有效。
在 OpenCV 中,有函数 cv2.equalizeHist()可实现这一操作,其输入为灰度图像,输出即为直方图均衡后的图像。
3.11.1.1 示例
1 | # 导入 OpenCV |
第十二节 阈值处理
阈值处理是 OpenCV 的一项技术,依据所给阈值来分配像素值。在该处理过程中,每个像素值会与阈值比较,若小于阈值则设为 0,否则设为最大值(通常为 255)。这是很流行的分割技术,用于区分被视为前景的对象和其背景,阈值两侧有低于阈值和高于阈值两个区域。
在计算机视觉中,这种阈值处理在灰度图像上进行,所以最初需将图像转换到灰度颜色空间。其表达式为:若 f(x,y)<T,则 f(x,y)=0,否则 f(x,y)=255,其中 f(x,y)表示坐标像素值,T 表示阈值值。
在使用 Python 的 OpenCV 中,函数cv2.threshold用于阈值化。
语法: cv2.threshold(source,thresholdValue,maxVal,thresholdingTechnique)
参数:
source:输入图像数组(必须为灰度)。
thresholdValue:阈值,低于和高于该值的像素值将相应改变。
maxVal:可以分配给像素的最大值。
ThresholdingTechnique:要应用的阈值类型。
3.12.1 简单阈值处理
基本的阈值技术是二进制阈值。对于每个像素,应用相同的阈值。如果像素值小于阈值,则设置为 0,否则设置为最大值。
不同的简单阈值技术是:
- cv2.THRESH_BINARY:如果像素强度大于设置的阈值,则值设置为 255,否则设置为 0(黑色)。
- cv2.THRESH_BINARY_INV:cv2.THRESH_BINARY 的反转或相反情况。
- cv2.THRESH_TRUNC:如果像素强度值大于阈值,则将其截断为阈值。像素值设置为与阈值相同。所有其他值保持不变。
- cv2.THRESH_TOZERO:像素强度设置为 0,对于所有像素强度,小于阈值。
- cv2.THRESH_TOZERO_INV:cv2.THRESH_TOZERO 的反转或相反情况。

3.12.1.1 示例
1 | import cv2 |
3.12.2 自适应阈值
在前一小节中已对不同类型的简单阈值技术进行了解释。还有一种阈值技术即自适应阈值。
在简单阈值处理中采用的是全局阈值,它始终恒定不变。所以在不同区域照明条件发生变化时,恒定的阈值就难以发挥作用。而自适应阈值处理是针对较小区域来计算阈值的方法,这使得不同区域针对照明变化会有不同的阈值,我们可以通过 cv2.adaptiveThreshold 来实现这一目的。
语法: cv2.adaptiveThreshold(source, maxVal, adaptiveMethod, thresholdType, blocksize, constant)
参数:
source:输入图像数组(单通道,8 位或浮点)
maxVal:可以分配给像素的最大值。
AdaptiveMethod:自适应方法决定如何计算阈值。
- cv2.ADAPTIVE_THRESH_MEAN_C:阈值 =(邻域区域值的平均值 - 常数值)。换句话说,它是一个点的 blockSize×blockSize 邻域的平均值减去常数。
- cv2.ADAPTIVE_THRESH_GAUSSIAN_C:阈值 =(邻域值的高斯加权总和 – 常数值)。换句话说,它是一个点的 blockSize×blockSize 邻域的加权和减去常数。
ThresholdType:要应用的阈值类型。
blockSize:用于计算阈值的像素邻域的大小。
constant:从邻域像素的平均值或加权和中减去的常数值。

3.12.2.1 示例
1 | import cv2 |
3.12.3 大津阈值
在前文已阐释了简单阈值与自适应阈值。于简单阈值处理时,运用始终不变的阈值全局值。而在自适应阈值处理中,是针对较小区域来计算阈值,不同区域对照明变化会有不同的阈值。
在 Otsu 阈值法中,阈值并非人为选择,而是自动确定。考虑双峰图像(即具有两个不同的图像值),所生成的直方图含有两个峰值。故而,通常的条件是选取位于两个直方图峰值中间的阈值。我们运用传统函数 cv2.threshold 并将 cv2.THRESH_OTSU 作为额外标志。
语法: cv2.threshold(源、thresholdValue、maxVal、thresholdingTechnique)
参数:
- source:输入图像数组(必须为灰度)。
- thresholdValue:阈值,低于和高于该值的像素值将相应改变。
- maxVal:可以分配给像素的最大值。
- ThresholdingTechnique:要应用的阈值类型。
3.12.3.1 示例
1 | import cv2 |
第十三节 OpenCV 过滤颜色
在 OpenCV 中,颜色分割或颜色过滤被广泛运用于识别具有特定颜色的特定对象或区域。其中,最为广泛应用的是 RGB 颜色空间,其被称作加法颜色空间,缘由是三种颜色阴影相加来为图像赋予颜色。
若要识别特定颜色的区域,需设定阈值并创建遮罩以分隔不同颜色。而 HSV 颜色空间在此目的上更为有用,因其空间中的颜色更具局部性,故而能够轻松实现分离。颜色过滤有着众多应用和用例,例如密码学、红外分析、易腐食品的食品保存等。
在这类情形中,可利用图像处理的概念来找出或提取特定颜色区域。对于颜色分割而言,我们仅需阈值或者了解某一颜色空间中颜色的下限和上限范围,其在色相-饱和度-值颜色空间中效果最为理想。在指定要分割的颜色范围后,需要相应地创建掩模,利用该掩模能够分离出特定的感兴趣区域。
3.13.1 示例
1 | import cv2 |
第十四节 OpenCV 彩色图片去噪
图像去噪是指从噪声图像中重建信号的过程。去噪是为了消除图像中不需要的噪声,以便以更好的形式对其进行分析。它指的是主要的预处理步骤之一。
opencv 中有四个函数用于不同图像的去噪。
语法: cv2.fastNlMeansDenoisingColored( P1, P2, float P3, float P4, int P5, int P6)
参数:
P1 –源图像阵列
P2 –目标图像阵列
P3 –用于计算权重的模板补丁的大小(以像素为单位)。
P4 –用于计算给定像素的加权平均值的窗口大小(以像素为单位)。
P5 –调节亮度分量滤波器强度的参数。
P6 –与上面相同,但用于颜色分量 // 不用于灰度图像。
3.14.1 示例
1 | # 导入库 |
第十五节 图像边缘图、图像热图、光谱图像图
3.15.1 图像边缘图
边缘图可以通过拉普拉斯、索贝尔等各种滤波器来获得。这里,我们使用拉普拉斯来生成边缘图。
1 | # 导入 cv2 模块 |
3.15.2 图像热图
在热图表示中,矩阵中包含的各个值表示为颜色。
1 | # 导入 matplotlib 和 cv2 |
3.15.3 光谱图像图
光谱图像图获取场景图像中每个像素的光谱。
1 | import matplotlib.pyplot as plt |
第十六节 OpenCV 查找轮廓坐标
在本文中,我们要学习借助 OpenCV 找到轮廓坐标。轮廓定义为沿图像边界连接相同强度所有点的线,其在形状分析、找感兴趣对象大小及对象检测等方面很便捷。
我们会用 OpenCV 的 findContour()函数来从图像中提取轮廓。
方法如下:
轮廓每个顶点的坐标藏在轮廓自身中。此方法里,我们将利用 numpy 库把轮廓所有坐标转化为线性数组,该线性数组包含每个轮廓的 x 与 y 坐标。
关键点在于数组中的第一个坐标永远是最顶部顶点的坐标,借此可帮助检测图像的方向。
以下代码中,我们将使用“test.jpg”图像来查找轮廓并打印图像本身上顶点的坐标。
输入图像:
3.16.1 示例
1 | import numpy as np |
第十七节 OpenCV 图片修复
图像修复是去除图像上的损坏(例如噪音、笔划或文本)的过程。它对于修复可能有划痕边缘或墨点的旧照片特别有用。这些可以通过这种方法以数字方式删除。图像修复的工作原理是用与相邻像素相似的像素替换损坏的像素,从而使它们不显眼并帮助它们与背景很好地融合。考虑下图。

该图像右侧有一些标记。为了修复这个图像,我们需要一个mask,它本质上是一个黑色图像,上面有白色标记来指示需要校正的区域。在这种情况下,掩码是在 GIMP 上手动创建的。
但不用担心。您无需学习如何使用 GIMP 工具。即使您知道如何使用 OpenCV,也可以轻松创建以下掩码。

3.17.1 在 OpenCV 中手动创建掩模
我们将按照以下步骤使用 OpenCV python 创建掩模:
- 读取损坏的图像
- 获取图像的形状(高度和宽度)
- 将损坏图像中的所有像素转换为我们想要的输出,即将所有黑色像素变为白色,将除黑色之外的其他剩余像素变为黑色
- 我们会将蒙版保存为 .jpg 格式或其他格式(根据您的要求)
1 | import cv2 |
如果运行上面的代码块,您可以看到以下结果(使用 OpenCV 使用上面的cat_damagged图像创建的掩码):

3.17.2 图像修复
修复算法方面,OpenCV 实现了两种:
一是“基于快速行进方法的图像修复技术”(Alexandru Telea,2004),其基于快速行进方法(FMM),算法先查看待修复区域,从边界像素开始,再转向边界内像素,将每个待修复像素替换为背景中像素的加权和,给予较近像素和边界像素更多权重;
二是 “Navier-Stokes、流体动力学以及图像和视频修复”(Bertalmio、Marcelo、Andrea L. Bertozzi 和 Guillermo Sapiro,2001),该算法受偏微分方程启发,从边缘(已知区域)开始向未知区域传播等光线(连接相同强度点的线),最后最小化区域差异以填充颜色。
FMM 可通过 cv2.INPAINT_TELEA 调用,Navier-Stokes 可通过 cv2.INPAINT_NS 调用。以下 Python 代码使用 Navier-Stokes 修复猫的图像。
1 | import numpy as np |
输出图像:

第十八节 图像的强度变换操作
将强度变换应用于图像以进行对比度操作或图像阈值处理。这些是在空间域中,即它们直接对当前图像的像素执行,而不是对图像的傅立叶变换执行。以下是常用的强度变换:
- 负片图像(线性):将图像的亮度值反转,使黑暗区域变为白色,明亮区域变为黑色。
- log 转换:将图像的亮度值映射为其对数,使暗区域变亮,亮区域变暗。
- 幂律(伽马)变换:通过调整幂次来改变图像的对比度,使图像更清晰或更模糊。
- 分段线性变换函数:根据不同的灰度范围,对图像进行不同的线性变换,以实现特定的效果。
18.1 负片转换
在 OpenCV 中,可以使用cv2.convertTo函数实现线性变换,将图像中的每个像素乘以一个常数k并加上另一个常数b,即y = kx + b。该函数常用于调整图像亮度和对比度等方面。
以下是一个使用 Python 语言实现的示例代码:
1 | import cv2 |
函数接受三个参数:图像、对比度k和亮度b。在函数内部,使用cv2.convertTo函数将图像从 BGR 颜色空间转换为灰度颜色空间,并将对比度和亮度应用于图像。
18.2 log 转换
对数变换是一种图像增强技术,它将图像的像素值进行对数运算,从而改变图像的对比度和亮度。通过对数变换,可以使图像的暗区域变得更亮,亮区域变得更暗,从而增强图像的对比度。
在 OpenCV 中,可以使用cv2.log函数来执行对数变换。该函数接受一个输入图像和一个可选的底数参数。默认情况下,底数为$e$(自然对数),但也可以指定其他底数,如$2$。
需要注意的是,对数变换可能会导致像素值溢出或失真。因此,在实际应用中,可能需要根据具体情况进行适当的调整和处理。
在数学上,对数变换可以表示为$s = c \cdot log(1+r)$。这里,$s$是输出强度,$r>=0$是像素的输入强度,$c$是缩放常数。 $c$由$\frac{255}{log(1 + m)}$给出,其中 $m$ 是图像中的最大像素值。这样做是为了确保最终像素值不超过 $(L-1)$ 或 $255$。实际上,对数变换将窄范围的低强度输入值映射到宽范围的输出值。
1 | import cv2 |
18.3 幂律(伽马)变换
伽玛校正对于在屏幕上正确显示图像非常重要,可以防止从具有不同显示设置的不同类型的显示器观看时出现图像漂白或变暗的情况。这样做是因为我们的眼睛以伽玛曲线感知图像,而相机以线性方式捕捉图像。
幂律(伽马)变换可以在数学上表示:
$$
s=cr^\gamma
$$
- $s$:表示经过变换后的输出值。
- $c$:通常是一个常数,用于调整整体的缩放比例。
- $r$:表示输入值,一般是原始的像素值或其他数据值。
- $\gamma$:即伽马值,它决定了变换的性质,对输出结果的对比度等特征有重要影响。不同的伽马值会产生不同的变换效果,如增强或减弱对比度等。
下面是应用伽马校正的 Python 代码:
1 | import cv2 |
不同伽马值的伽马校正输出不同的图片。可以尝试 Gamma = 0.1、Gamma = 0.5、Gamma = 1.2、Gamma = 2.2。
当 gamma>1(由图表上“n 次方”标签对应的曲线表示),像素强度降低,即图像变暗。另一方面,gamma<1(由图表上与“nth root”标签相对应的曲线表示),强度增加,即图像变得更亮。
18.4 分段线性变换函数
顾名思义,这些函数本质上并不完全是线性的。然而,它们在某些 x 区间之间是线性的。最常用的分段线性变换函数之一是对比度拉伸。对比度可以定义为:
$$
Contrast = \frac{I_{max} - I_{min}}{I_{max} + I_{min}}
$$
此过程扩展了图像中的强度级别范围,使其跨越相机/显示器的全部强度。下图显示了对比度拉伸对应的图表。
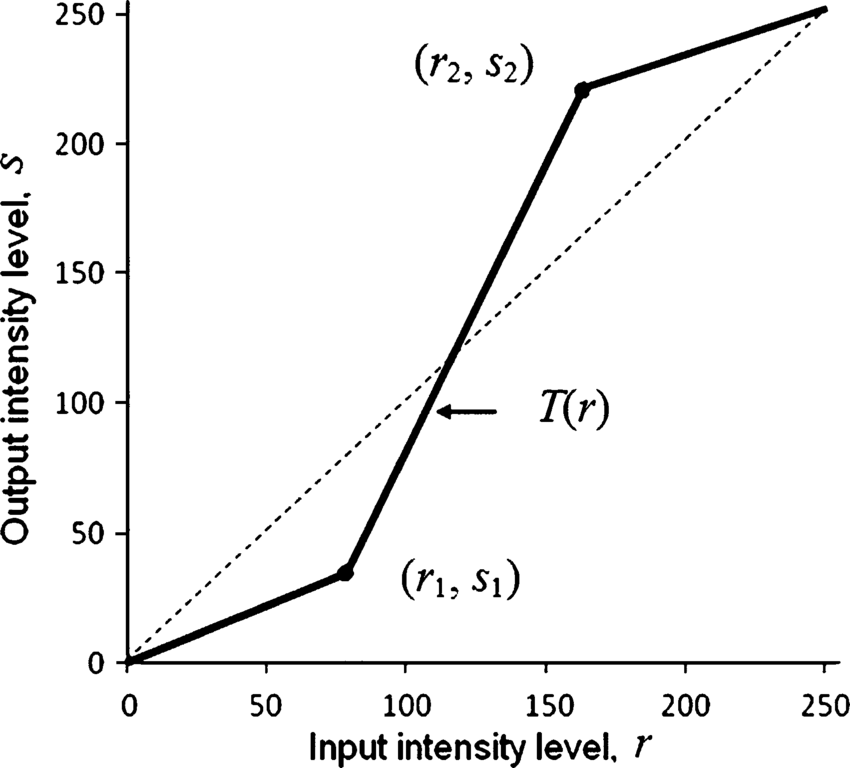
使用 (r1, s1)、(r2, s2) 作为参数,该函数通过本质上降低暗像素的强度并增加亮像素的强度来拉伸强度级别。
如果r1 = s1 = 0 和r2 = s2 = L-1,函数在图中变成一条直线虚线(没有任何效果)。该函数是单调递增的,因此像素之间的强度级别顺序得以保留。
下面是执行对比度拉伸的 Python 代码:
1 | import cv2 |
第十九节 OpenCV 进行图像配准
图像配准是一种数字图像处理技术,可以帮助我们对齐同一场景的不同图像。例如,人们可以从不同的角度查看一本书的图片。以下是一些显示摄像机角度多样性的实例。



现在,我们可能想要将特定图像“对齐”到与参考图像相同的角度。在上面的图像中,人们可能会认为第一张图像是“理想”的封面照片,而第二张和第三张图像则不能很好地用作书籍封面照片。图像配准算法帮助我们将第二张和第三张图片对齐到与第一张图片相同的平面。
19.1 图像配准的步骤
图像配准可视为简单的坐标变换,其算法流程如下:
- 将两个图像都转换为灰度图像。
- 将待对齐图像的特征与参考图像进行匹配,并存储相应关键点的坐标,关键点是用于计算变换的选定的突出点,描述符是图像梯度的直方图用于表征关键点外观,使用 OpenCV 库中的 ORB 来获取关键点及其相关描述符。
- 匹配两个图像之间的关键点,使用 BFMatcher,BFMatcher.match()检索最佳匹配,BFMatcher.knnMatch()检索用户指定的前 K 个匹配。
- 挑选最热门的匹配并去除嘈杂匹配。
- 计算同态变换。
- 将该变换应用于原始未对齐图像以获得输出图像。
19.2 图像配准的应用
图像配准的一些有用的应用包括:
- 将各种场景(可能具有或不具有相同的相机对齐方式)拼接在一起以形成连续的全景镜头。
- 将文档的相机图像与标准对齐方式对齐,以创建逼真的扫描文档。
- 对齐医学图像以更好地观察和分析。
19.3 示例
1 | import cv2 |
第二十节:使用 OpenCV 进行背景减除
背景减除在日常生活中有诸多应用场景,如用于对象分割、安全强化、行人追踪、访客数量统计、交通车辆数量统计等,其能够学习并识别前景掩模。
顾名思义,背景减除可以减去或去除图像中的背景部分,其输出为二值分割图像,从本质上提供了图像中非静止物体的信息。然而,这种寻找非静止部分的概念存在一个问题,即移动物体的阴影可能是移动的,有时会被归类到前景中。
流行的背景减除算法包括:
- BackgroundSubtractorMOG:这是一种基于高斯混合的背景分割算法。
- BackgroundSubtractorMOG2:采用相同概念,但主要优势在于即便亮度发生变化仍能保持稳定,且在帧中阴影识别方面有更好的能力。
- 几何多重网格:利用统计方法和每像素贝叶斯分割算法。
20.1 实例
1 | import numpy as np |
第二十一节:利用移动平均概念在图像中减去背景
背景减除是一项可从背景中分离出前景元素的技术,其通过生成前景蒙版得以实现。此技术常用于静态摄像机中对动态移动物体的检测,且对目标跟踪至关重要,同时存在多种背景扣除技术。
在本小节中,我们探讨运行平均值的概念。该概念利用函数的运行平均值来区分前景与背景。
具体而言,对视频序列在特定的一组帧上进行剖析,在这一帧序列期间,计算当前帧和之前帧的运行平均值,从而获得背景模型,而在视频排序过程中引入的任何新对象都会成为前景的一部分。接着,当前帧会保留新引入的对象和背景,然后计算背景模型(其为时间的函数)与当前帧(其包含新引入的对象)之间的绝对差。计算运行平均值使用如下等式:
$$
det(x,y) = (1 - alpha).dst(x,y) + alpha.src(x,y)
$$
21.1 运行平均法如何运作?
该程序的目标是根据参考帧和当前帧获得的差异来检测活动对象。我们不断将每一帧输入给给定的函数,该函数不断计算所有帧的平均值。然后我们计算帧之间的绝对差。使用的函数是**cv2.accumulateWeighted()**。
方法:cv2.accumulateWeighted(src, dst, alpha)
参数:
src:源图像。图像可以是彩色或灰度图像以及 8 位或 32 位浮点型。
dst:累加器或目标图像。它是 32 位或 64 位浮点。 注意:它应该具有与源图像相同的通道。另外,dst 的值应该首先预先声明。
alpha:输入图像的权重。 Alpha 决定更新的速度。如果您为此变量设置较低的值,则将对大量先前帧执行运行平均值,反之亦然。
21.2 示例
1 | import cv2 # 导入 OpenCV 库 |
我们还可以使用 cv2.RunningAvg() 来执行相同的任务,参数具有相同的含义作为 cv2.accumulateweighted() 的参数。
第二十二节 图像分割 GrabCut 算法提取图像中的前景
GrabCut 是一种交互式图像分割算法,由 Carsten Rother、Vladimir Kolmogorov 和 Andrew Blake 于 2004 年提出。它是一种基于图切割的算法,旨在将图像分割为前景和背景区域,使其对于诸如此类的应用特别有用图像编辑和对象识别。
该算法需要用户交互来初始化分割过程。通常,在图像中感兴趣的对象周围绘制一个矩形。然后,该算法根据矩形内外的颜色和纹理信息迭代地细化初始分割。

前景提取是图像分割的一部分,其目标是精确地描绘主要对象或主题(前景)并将其与图像的其余部分(背景)分开。
图像分割技术,包括语义分割或实例分割,有助于实现图像内前景的准确和详细的描绘。
22.1 GrabCut 算法如何用于图像分割?
区域绘制:在该算法中,区域是根据前景绘制的,在其上绘制一个矩形。这是包围我们的主要对象的矩形。区域坐标是根据理解前景掩模决定的,但可能会出现不完美的分割,标记为手动校正。
感兴趣区域(ROI)选择:感兴趣区域由要执行的前景和背景分割量决定,并由用户选择。 ROI 之外的所有内容都被视为背景并变成黑色。
高斯混合模型(GMM):然后使用高斯混合模型(GMM)对前景和背景进行建模。然后,根据用户提供的数据,GMM 学习并为未知像素创建标签,并且根据颜色统计对每个像素进行聚类。
图生成:根据该像素分布生成图,其中像素被视为节点,并添加两个附加节点,即源节点和汇节点。所有前景像素都连接到源节点,每个背景像素都连接到接收器节点。
如果发现像素颜色存在巨大差异,则为该边缘分配较低的权重:
图分割算法:然后应用该算法对图进行分割。该算法将图分割成两部分,借助成本函数将源节点和汇节点分开,该成本函数是被分割的边的所有权重之和。
前景-背景标记:分割后,连接到 Source 节点的像素被标记为前景,连接到 Sink 节点的像素被标记为背景。
语法: cv2.grabCut(image, mask, rectangle, backgroundModel, foregroundModel, iterationCount [,mode])
参数:
image:输入 8 位 3 通道图像。
mask:输入/输出 8 位单通道掩码。当模式设置为 GC_INIT_WITH_RECT 时,掩码由函数初始化。
其元素可能具有以下值之一:
- GC_BGD定义了明显的背景像素。
- GC_FGD定义了明显的前景(对象)像素。
- GC_PR_BGD定义可能的背景像素。
- GC_PR_FGD定义可能的前景像素。
rectangle:它是包含分割对象的感兴趣区域。 ROI 之外的像素被标记为明显的背景。该参数仅
mode==GC_INIT_WITH_RECT时使用。backgroundModel:背景模型的临时数组。
foregroundModel:前景模型的临时数组。
iterationCount:算法在返回结果之前应进行的迭代次数。请注意,可以通过使用
mode=GC_INIT_WITH_MASK或mode=GC_EVAL进一步调用来细化结果。mode:定义操作模式。
它可以是以下之一:
- GC_INIT_WITH_RECT:该函数使用提供的矩形初始化状态和掩码。之后,它运行算法的
iterCount次迭代。 - GC_INIT_WITH_MASK:该函数使用提供的掩码初始化状态。请注意,
GC_INIT_WITH_RECT和GC_INIT_WITH_MASK可以组合使用。然后,ROI 之外的所有像素都会自动使用GC_BGD进行初始化。 - GC_EVAL:该值意味着算法应该恢复。
- GC_INIT_WITH_RECT:该函数使用提供的矩形初始化状态和掩码。之后,它运行算法的
22.2 示例
示例所使用图片:

1 | import numpy as np # 导入 numpy 库 |
第二十三节 图像处理中的形态学操作
23.1 开运算
形态学操作用于提取在区域形状的表示和描述中有用的图像成分。形态学操作是一些依赖于图像形状的基本任务。它通常在二进制图像上执行。它需要两个数据源,一个是输入图像,另一个称为结构元素。形态学运算符将输入图像和结构元素作为输入,然后使用集合运算符将这些元素组合起来。输入图像中的对象根据图像形状的属性进行处理,这些属性在结构元素中编码。
开运算类似于腐蚀,因为它倾向于从前景像素区域的边缘去除明亮的前景像素。该运算符的影响是保护与结构元素相似的前景区域,或者能够完全包含结构元素,同时去除所有其他前景像素区域。开运算用于去除图像中的内部噪声。
开运算在数学上可以表示为:先进行腐蚀操作,再进行膨胀操作。设原始图像为 A,结构元素为 B,腐蚀操作记为 Θ,膨胀操作记为 ⊕,则开运算记为 A◦B,可表示为:
$$
A◦B = (AΘB)⊕B 。
$$

开运算示例:
1 | import cv2 |
系统将定义的蓝皮书识别为输入,并借助 Opening 函数消除和简化感兴趣区域的内部噪声。
23.3 闭运算
在上一小节中,指定了开运算,即在膨胀后应用腐蚀运算。它有助于消除图像中的内部噪声。关闭操作与打开操作类似。合闸操作的基本前提是合闸是分闸的相反操作。它被简单地定义为使用与开运算相同的结构元素进行膨胀,然后进行腐蚀。
设原始图像为 A,结构元素为 B,膨胀操作记为 ⊕,腐蚀操作记为 Θ,则关运算记为 A·B,可表示为:
$$
A·B = (A⊕B)ΘB
$$
语法: cv2.morphologyEx(image, cv2.MORPH_CLOSE, kernel)
参数:
image:输入图像数组。
cv2.MORPH_CLOSE:应用形态闭运算。
kernel:结构元素。
闭运算示例:
1 | # 组织导入 |
23.5 梯度运算
在前面的两小节中,指定了 Opening 操作和 Closing 操作。在本文中,详细阐述了另一种形态学操作:梯度。
它用于生成图像的轮廓。渐变有两种类型:内部渐变和外部渐变。内部渐变增强了比背景亮的对象的内部边界和比背景暗的对象的外部边界。对于二值图像,内部梯度生成前景图像对象的内部边界的掩模。
语法: cv2.morphologyEx(image, cv2.MORPH_GRADIENT, kernel)
参数:
image: 输入图像
cv2.MORPH_GRADIENT: 应用形态梯度运算
kernel: 结构元素
1 | # 组织导入 |
输出图像帧显示在蓝皮书和左上角的蓝色对象上生成的轮廓。
第三章 实验部分
第一节 读取图片
1 | import numpy as np |
第二节 灰度转换
1 | #导入CV模块 |
第三节 尺寸修改
1 | #导入CV模块 |
第四节 绘制矩形
1 | #导入CV模块 |
第五节 人脸检测
Haar 特征是用于图像处理和计算机视觉的数字图像特征,由 Viola 和 Jones 于 2001 年提出,常用于面部识别与人脸检测。
其基本思想是将图像划分多个矩形区域,计算像素值差异以获得描述图像特征的数值,矩形位置通过类似人脸外接矩形的检测窗口确定。Haar 特征分为四类(边缘特征、线性特征、中心特征、对角线特征),可组合成特征模板,通过改变模板大小和位置能在图像子窗口中穷举大量特征。
Haar cascade 采用“滑动窗口”方法,在图像中不断“滑动检测窗口”来匹配人脸。需用 scaleFactor 参数设置缩小比例来逐步缩小检测图像,该参数越大计算速度越快,但可能错过某些大小的人脸,通常可在 1 到 1.5 之间根据图像像素值设置。经过多次迭代会检测出很多人脸,可通过将 minNeighbors 设为 0 来验证。minNeighbors 参数的作用是只有“邻居”大于等于该值的结果才被认为是正确结果。
Haar 特征的主要优势是计算速度快,可使用积分图像在常数时间内计算任意尺寸的 Haar 特征,AdaBoost 算法可将多个弱分类器组合成更强大的分类器。
核心原理:
- 使用 Haar-like 特征做检测
- Integrallmage:积分图加速特征计算
- AdaBoost:选择关键特征,进行人脸和非人脸分类
- Cascade:级联,弱分类器成为强分类器
1 | pip install opencv-python |
1 | # 导入opencv |
第六节 视频检测
下载,右键另存为:Haarcascade_frontalface_default.xml
1 | # 导入opencv |