Numpy基础
第一章:Numpy简介
1.1 前置知识
- 重点掌握Python的内置数据结构:字符串、列表、元组,集合和字典。
- 重点掌握序列的索引和切片访问的相关操作
- 重点掌握列表、集合和字典的推导式
- 重点掌握Lambda 表达式
- 重点掌握Python函数式编程的基础函数:filter()、map()和reduce()。
1.2 Numpy简介和特点
- NumPy全称为【Numerical Python】,它是一个开源的Python 数据分析和科学计算库。
- NumPy是我们后期学习Pandas(数据分析)、SciPy(科学计算)和 Matplotlib(绘图库)的基础。
- NumPy的官网是https://numpy.org/
- NumPy 底层是使用 C 语言实现的,速度快。
- NumPy提供数据结构(即数组)比Python 内置数据结构访问效率更高。
- 支持大量高维度数组与矩阵运算。
- 提供大量的数学函数库。
第二章 Numpy的安装
2.1 安装Anaconda
Anaconda 是一个开源的 Python 发行版本,其包含了conda、Python 等 1500 多个科学包及其依赖项。
- Anaconda官网:https://www.anaconda.com
- 清华大学开源软件镜像站:https://mirrors.tuna.tsinghua.edu.cn
2.2 Python的开发工具
- Python shell:这是一个命令行界面,允许用户直接输入Python命令并执行。它非常适合快速测试代码片段或进行交互式编程。
- IPython shell:基于Python shell,IPython提供了更多的交互式功能,如自动完成、额外的帮助功能和更丰富的历史记录。
- Jupyter Notebook:这是一个开源的Web应用程序,允许你创建和共享包含实时代码、方程、可视化和解释性文本的文档。它特别适合数据分析和机器学习项目。
- Pycharm:Pycharm是由JetBrains开发的一个强大的Python集成开发环境(IDE),提供代码智能感知、项目管理、版本控制和其他许多高级功能。
- Python IDLE:这是Python官方提供的一个简单集成开发环境,适合初学者进行Python学习,提供了一个图形用户界面。
- Spyder:Spyder是专门为科学计算和数据分析设计的IDE,它集成了许多科学家和工程师需要的功能,如变量浏览器、代码编辑器和结果可视化。
- Sublime Text:Sublime Text是一个代码编辑器,不是完整的IDE,但它支持Python编程,并可以通过安装插件来扩展其功能,如Python代码高亮、代码自动完成等。
- Eclipse Pydev 插件:Eclipse是一个流行的跨平台IDE,通过安装Pydev插件,可以支持Python开发,提供代码补全、调试等功能。
- Visual Studio Code:这是Microsoft开发的一个轻量级但功能强大的源代码编辑器,支持包括Python在内的多种编程语言。通过安装适当的扩展,它能够提供代码高亮、智能感知和调试工具等特性。
第三章 一维数组
3.1 一维数组的介绍
- NumPy中最重要的数据结构是数组对象,即numpy.ndarray
- 用于存放同类型元素的集合
- 每个元素在内存中都有相同存储大小的区域
- 我们可以通过使用array函数来创建一维数组
1
numpy.array(object)
- 其中,参数object类型可以是列表或者元组。
- 数组只能保存相同的数据类型,而列表可以保存任何类型的数据。
1 | import numpy as np |
3.2 数组的数据类型
3.2.1 整数数据类型
| 名称 | 类型代码 | 描述 |
|---|---|---|
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) | |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 | |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) | |
| int8 | i1 | 字节(-128 to 127) |
| int16 | i2 | 整数(-32768 to 32767) |
| int32 | i4 | 整数(-2147483648 to 2147483647) |
| int64 | i8 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | u1 | 无符号整数(0 to 255) |
| uint16 | u2 | 无符号整数(0 to 65535) |
| uint32 | u4 | 无符号整数(0 to 4294967295) |
| uint64 | u8 | 无符号整数(0 to 18446744073709551615) |
3.2.2 浮点数数据类型
| 名称 | 类型代码 | 描述 |
|---|---|---|
| float_ | float64 类型的简写 | |
| float16 | f2 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | f4或f | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | f8或d | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
3.2.3 复数数据类型
| 名称 | 类型代码 | 描述 |
|---|---|---|
| complex_ | complex128 类型的简写,即 128 位复数 | |
| complex64 | c8 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | c16 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
3.2.4 其他数据类型
| 名称 | 类型代码 | 描述 |
|---|---|---|
| bool_ | 布尔型数据类型(True 或者 False) | |
| string_ | S | Ascii字符串,例如:S7代表长度为7的ASCII字符串 |
| unicode_ | U | Unicode字符串,例如:U5代表长度为5的Unicode编码字符串 |
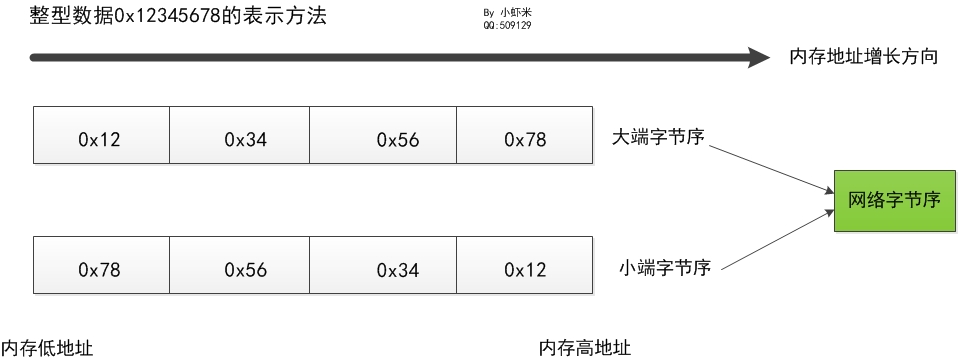
字节序
大端字节序(Big Endian):在存储多字节数据时,最大的字节存储在地址最低的位置。例如,对于一个32位的数据0x12345678,在大端字节序中,它按照0x12 0x34 0x56 0x78的顺序存储。
小端字节序(Little Endian):在存储多字节数据时,最小的字节存储在地址最低的位置。例如,对于一个32位的数据0x12345678,在小端字节序中,它按照0x78 0x56 0x34 0x12的顺序存储。
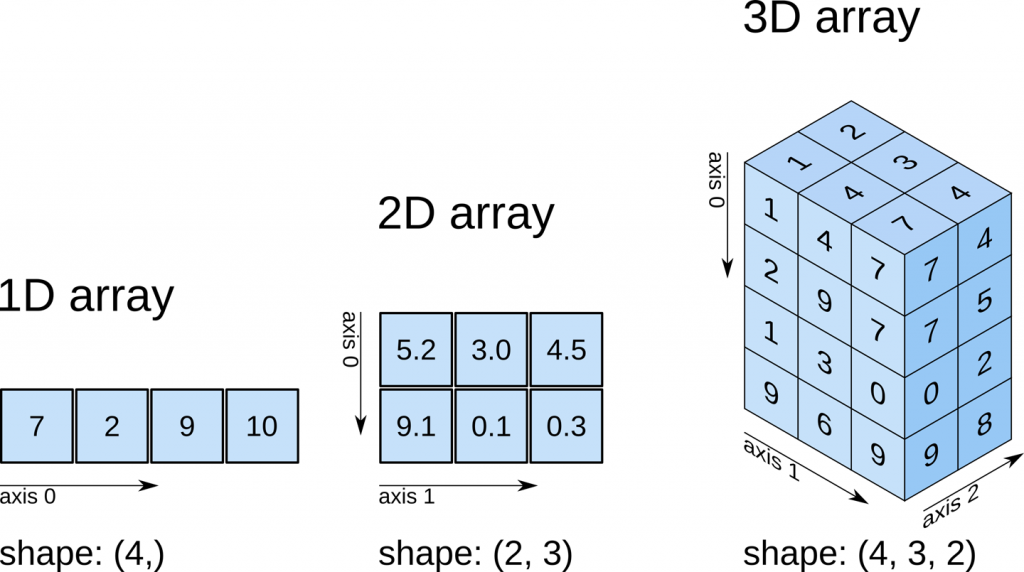
3.3 其他创建一维数组的函数
3.3.1 arange函数
我们可以使用arange()函数创建数值范围并返回数组对象
1 | numpy.arange(start,stop, step, dtype) |
- start: 开始值,默认值为0,包含开始值>
- stop: 结束值,不包含结束值>
- step: 步长,默认值为1,该值可以为负数
- dtype: 数组元素类型
3.3.2 linspace函数
使用linspace()函数创建等差数组
1 | numpy.linspace(start, stop, num, endpoint, retstep, dtype) |
- num: 设置生成的元素个数
- endpoint: 设置是否包含结束值,False是不包含,True是包含,默认值是True
- retstep: 设置是否返回步长(即公差),False是不返回,默认值是False,True是返回,当值为True时,返回值是二元组,包括数组和步长
3.3.3 logspace函数
使用logspace()函数创建等比数组
1 | numpy.logspace(start, stop, num, endpoint, base, dtype) |
- start: 开始值,值为base**start
- stop: 结束值,值为base**stop
- base:底数
3.3.4 例子:
1 | import numpy as np |
第四章 二维数组
4.1 创建二维数组
4.1.1 array()函数
通过使用array 函数来创建二维数组
1 | numpy.array(object) |
其中,参数object类型可以是列表或者元组。
1 | import numpy as np |
4.2 数组的轴
二维数组有两个轴,轴索引分别为0和1
4.2.1 数组转置
可以使用数组对象的属性T,将数组进行转置
1 | import numpy as np |
4.3 其他创建二维数组的函数
4.3.1 ones函数
根据指定的形状和数据类型生成全为1的数组
1 | numpy.ones(shape, dtype=None) |
shape: 数组的形状
4.3.2 zeros函数
根据指定的形状和数据类型生成全为0的数组
1 | numpy.zeros(shape, dtype=None) |
shape: 数组的形状
4.3.3 full函数
根据指定的形状和数据类型生成数组,并用指定数据填充
1 | numpy.full(shape, fill_value, dtype=None) |
fill_value: 指定填充的数据
4.3.4 identity函数
创建单位矩阵(即对角线元素为1,其他元素为0的矩阵)
1 | numpy.identity(n,dtype=None) |
n: 数组形状
4.3.5 示例
1 | import numpy as np |
第五章 数组的访问
5.1 索引访问
一维数组索引访问与Python内置序列类型索引访问一样
1 | ndarray[index] |
5.2 切片访问
一维数组切片访问与Python内置序列类型切片访问一样
1 | ndarray[start:end] |
5.2.1 一维数组切片访问
一维数组切片访问与Python内置序列类型切片访问一样
1 | ndarray[start:end] |
注意,切片包括start位置元素,但不包括end位置元素
5.2.2 二维数组切片访问
1 | ndarray[所有0轴切片,所有1轴切片] |
1 | import numpy as np |
5.3 布尔索引
传递布尔索引,从数组中过滤出我们需要的元素
注意:
- 布尔索引必须与要索引的数组形状相同,否则会引发IndexError错误。
- 布尔索引返回的新数组是原数组的副本,与原数组不共亨相同的数据空间,即新数组的修改不会影响原数组,这是所谓的深层复制。
1 | import numpy as np |
1 | a3 = np.array([1, 2, 3]) |
5.4 花式索引
什么是花式索引?
- 索引为整数列表
- 索引为一维整数数组
- 索引为二维整数数组
注意:
- 花式索引返回的新数组与花式索引数组形状相同
- 花式索引返回的新数组属于深层复制
- 二维数组上每一个轴的索引数组形状相同
1 | import numpy as np |
第六章 数组的操作
6.1 连接数组
6.1.1 concatenate函数
该函数指沿指定的轴连接多个数组
1 | numpy.concatenate((al, a2, ...), axis) |
- a1,a2 是要连接的数组。注意,除了指定轴外,其他轴元素个数必须相同。
- axis 是沿指定轴的索引,默认为0轴
6.1.2 vstack函数
沿垂直堆叠多个数组,相当于concatenate函数axis=0情况
1 | numpy.vstack((al, a2)) |
注意,1轴上元素个数相同
6.1.3 hstack()函数
沿水平堆叠多个数组,相当于concatenate()函数axis=1情况
1 | numpy.hstack((a1, a2)) |
注意,0轴上元素个数相同
6.1.4 示例
1 | import numpy as np |
6.2 分割数组
6.2.1 split()函数
该函数指沿指定的轴分割多个数组
1 | numpy.split(ary, indices_or_sections, axis) |
- ary 是要被分割的数组
- indices_or_sections 是一个整数或数组,如果是整数就用该数平均分割;如果是数组,则为沿指定轴的切片操作。
- axis 指轴的分割方向,默认为0轴。
6.2.2 vsplit()函数
该函数指沿垂直方向分割数组,相当于split函数axis=0情况
1 | numpy.vsplit(ary, indices_or_sections) |
6.2.3 hsplit()函数
该函数指沿水平方向分割数组,相当于split0)函数axis=1情况
1 | numpy.hsplit(ary, indices_or_sections) |
6.2.4 例子
1 | import numpy as np |
6.3 算术运算
数组对象可以使用Python原生的算术运算符
| 运算符 | 描述 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| // | 整除,返回商的整数部分 |
| % | 取余 |
| ** | 次幂 |
1 | # 一维数组的算术运算 |
6.4 数组广播
数组与标量或者不同形状的数组进行算术运算时候,就会发生数组广播
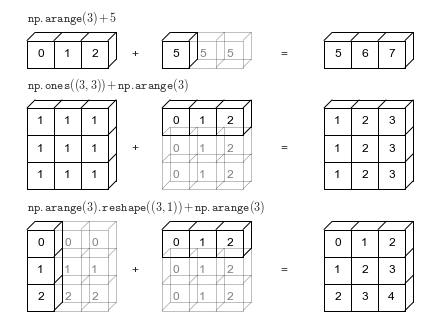
数组与不同形状的数组进行算术运算时,会发生广播,需遵守以下广播原则:
- 先比较形状,再比较维度,最后比较对应轴长度
- 如果两个数组维度不相等,会在维度较低数组的形状左侧填充1,直到维度与高维数组相等
- 如果两个数组维度相等时,对应轴的长度相同或其中一个轴长度为1,长度为1的轴会被扩展,则兼容的数组可以广播。
1 | import numpy as np |
第七章 数组的常用函数
7.1 随机数函数
7.1.1 rand函数
该函数返回[0.0, 1.0)的随机浮点数,即大于等于0.0,且小于1.0的随机浮点数
1 | numpy.random.rand(d0, d1, .., dn) |
7.1.2 randint函数
该函数返回[low, high)的随机整数,如果high省略,则返回[0, low)的随机整数。
1 | numpy.random.randint(low, high, size, dtype) |
size表示数组的形状
7.1.3 normal函数
该函数返回正态分布随机数
1 | numpy.random.normal(loc, scale, size) |
- loc表示平均值
- scale表示标准差
7.1.4 randn()函数
该函数返回标准正态分布随机数,即平均数为0,标准差1的正太分布随机数
1 | numpy.random.randn(d0, d1, ..., dn) |
其中的d0、d1… 表示的是数组的形状
7.1.5 例子
1 | import numpy as np |
7.2 排序函数
7.2.1 sort函数
按照轴对数组进行排序,即轴排序
1 | numpy.sort(a, axis=-1, kind='quicksort', order=None) |
- a 表示要排序的数组
- axis 表示排序的轴索引,默认是-1,表示最后一个轴
- kind 表示排序类型。quicksort:快速排序,为默认值速度最快; mergesort:归并排序; heapsort:堆排序
- order 表示排序字段
7.2.2 argsort函数
按照轴对数组进行排序,后返回排序之前的索引值。
1 | numpy.argsort(a, axis=-1, kind='quicksort', order=None) |
- a 表示要排序的数组
- axis 表示排序的轴索引,默认是-1,表示最后一个轴
- kind 表示排序类型。quicksort:快速排序,为默认值速度最快; mergesort:归并排序; heapsort:堆排序
- order 表示排序字段
7.2.3 示例
1 | import numpy as np |
7.3 聚合函数
7.3.1 求和
使用NumPy中sum()函数
1 | numpy.sum(a, axis=None) |
使用NumPy中nansum()函数,该函数忽略NaN
1 | numpy.nansum(a, axis=None) |
使用数组对象的sum()方法
1 | numpy.ndarray.sum(axis=None) |
7.3.2 求最大值
使用NumPy中amax()函数
1 | numpy.amax(a, axis=None) |
使用NumPy中nanmax()函数,该函数忽略NaN
1 | numpy.nanmax(a,axis=None) |
使用数组对象的max()方法
1 | numpy.ndarray.max(axis=None) |
7.3.3 求最小值
使用NumPy中amin()函数
1 | numpy.amin(a, axis=None) |
使用NumPy中nanmin()函数,该函数忽略NaN
1 | numpy.nanmin(a,axis=None) |
使用数组对象的min()方法
1 | numpy.ndarray.min(axis=None) |
7.3.4 求平均值
使用NumPy中mean()函数
1 | Numpy.mean(a, axis=None) |
使用NumPy中nanmean()函数,该函数忽略NaN
1 | numpy.nanmean(a, axis=None) |
使用数组对象的mean()方法
1 | numpy.ndarray.mean(axis=None) |
7.3.5 求加权平均
使用NumPy中average()函数
1 | numpy.average(a, axis=None, weights=None) |
weights 表示权重
7.3.6 例子
1 | import numpy as np |
第八章 数组的保存和读取
8.1 数组的保存
8.1.1 save函数
该函数可以将一个数组保存至后缀名为”.npy”的二进制文件中
1 | numpy.save(file,arr, allow_pickle=True, fix imports=True) |
- file 表示文件名/文件路径
- arr 表示要存储的数组
- allow_pickle为布尔值,表示是否允许使用pickle来保存数组对象
- fix_imports为布尔值,表示是否允许在Pyhton2中读取Python3保存的数据
8.1.2 savez函数
该函数可以将多个数组保存到未压缩的后缀名为”.npz”的二进制文件中
1 | npmpy.savez(file) |
8.1.3 savez_compressed()函数
该函数可以将多个数组保存到压缩的后缀名为”.npz”的二进制文件中
8.1.4 例子
1 | import numpy as np |
8.2 数组的读取
读取”.npy”和”.npz”文件中的数组
1 | numpy.load(file, mmap_mode, allow_pickle, fix_imports) |
mmap_mode表示内存的映射模式,即在读取较大的NumPy数组时的模式,默认情况下是None
8.2.1 例子
1 | import numpy as np |