实验:从数据标注到PPYOLOE+模型训练
1. 数据标注
1.1 工具安装
数据标注是为机器学习模型提供标签或注释的过程,以帮助模型理解和学习数据。人类标注员根据任务类型,为数据样本添加不同类型的标签,如图像中的对象框或文本的情感标签。高质量的数据标注对于训练出好的模型至关重要。常见应用包括图像识别、文本分类等。
1 | 创建虚拟环境 |
1.2 将视频裁切成640x640的尺寸
可以用ps、剪映
将视频拖入ps,通过裁剪工具裁剪成1x1,调整菜单栏上的编辑-图像大小,修改成640x640。
为什么要640x640?因为模型入参就是640x640,避免多次转换。
1.3 安装视频转换图片工具
1 | pip install video-cli |
1.4 视频转图片
视频转换图片
1 | video-toimg your_video.mp4 |
开始标注:
1 | labelme your_video/ |
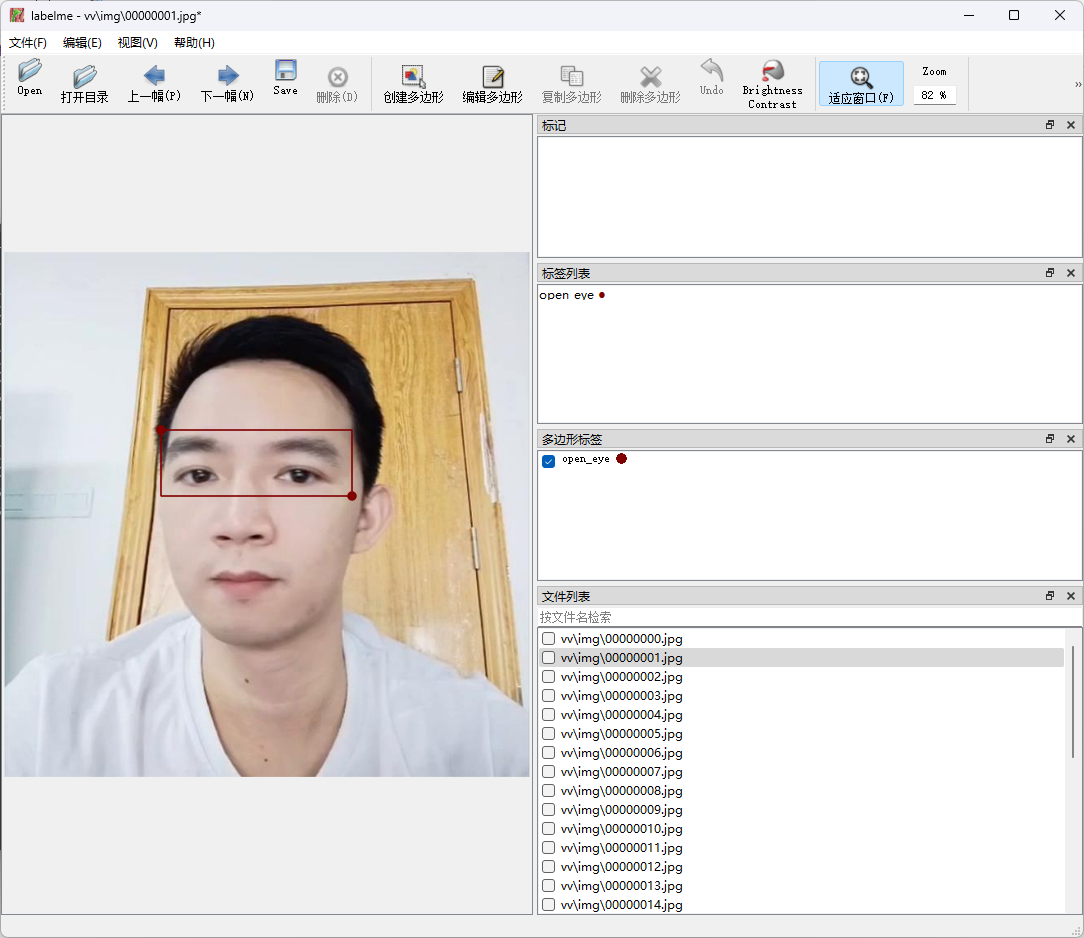
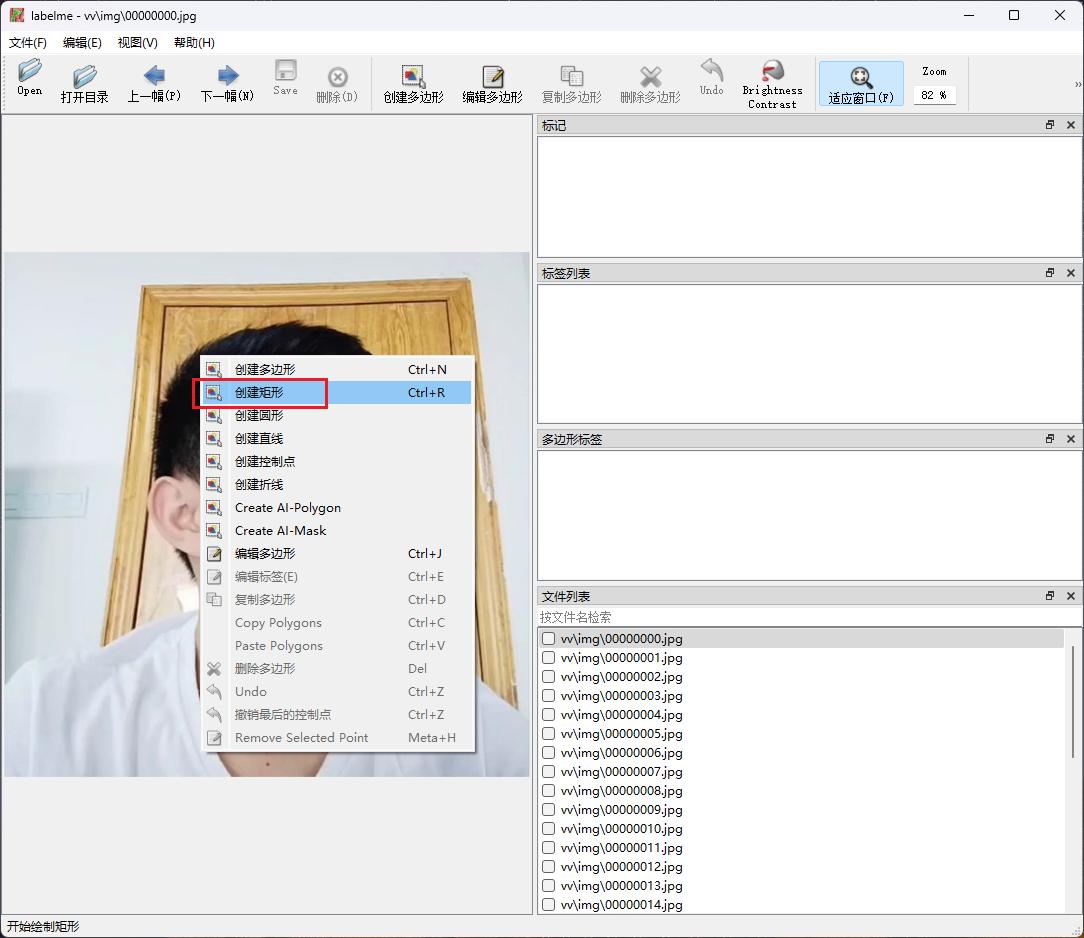
1.5 标注图片
在labelme虚拟环境,执行labelme vv

1.6 将标注的图片乱序
1 | import os |
1.7 依赖安装
1 | pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple |
1.8 转换成COCO格式并划分数据集
标注好数据后,如果图片与json文件在同一个文件夹,需要分开。可以新建两个文件夹,将图片放入img文件夹,将json放入json文件夹,然后执行如下命令:
80%划分为训练集、20%划分为验证集
1 | python tools/x2coco.py \ |
该命令是用于将 LabelMe 格式的数据转换为 COCO 格式的数据,以便在目标检测或图像分割任务中使用。以下是每个参数的中文说明:
| 参数 | 说明 |
|---|---|
| –dataset_type labelme | 表示输入的数据集格式为 LabelMe 格式。 |
| –json_input_dir | 指定 LabelMe 格式的 JSON 标注文件所在的目录路径。 |
| –image_input_dir | 指定包含图像文件的目录路径。 |
| –output_dir | 指定转换后的 COCO 格式数据将保存在哪个目录下。 |
| –train_proportion | 指定训练集占总数据集的比例,这里是 80%。 |
| –val_proportion | 指定验证集占总数据集的比例,这里是 20%。 |
| –test_proportion | 指定测试集占总数据集的比例,这里是 0%。 |
这个命令的作用是将 LabelMe 数据集转换为 COCO 数据集,并按照指定的比例划分为训练集和验证集,其中没有设置测试集(测试集比例为 0%)。转换后的数据将保存在指定的输出目录中,可以供后续在目标检测或图像分割模型训练中使用。
2. 模型训练
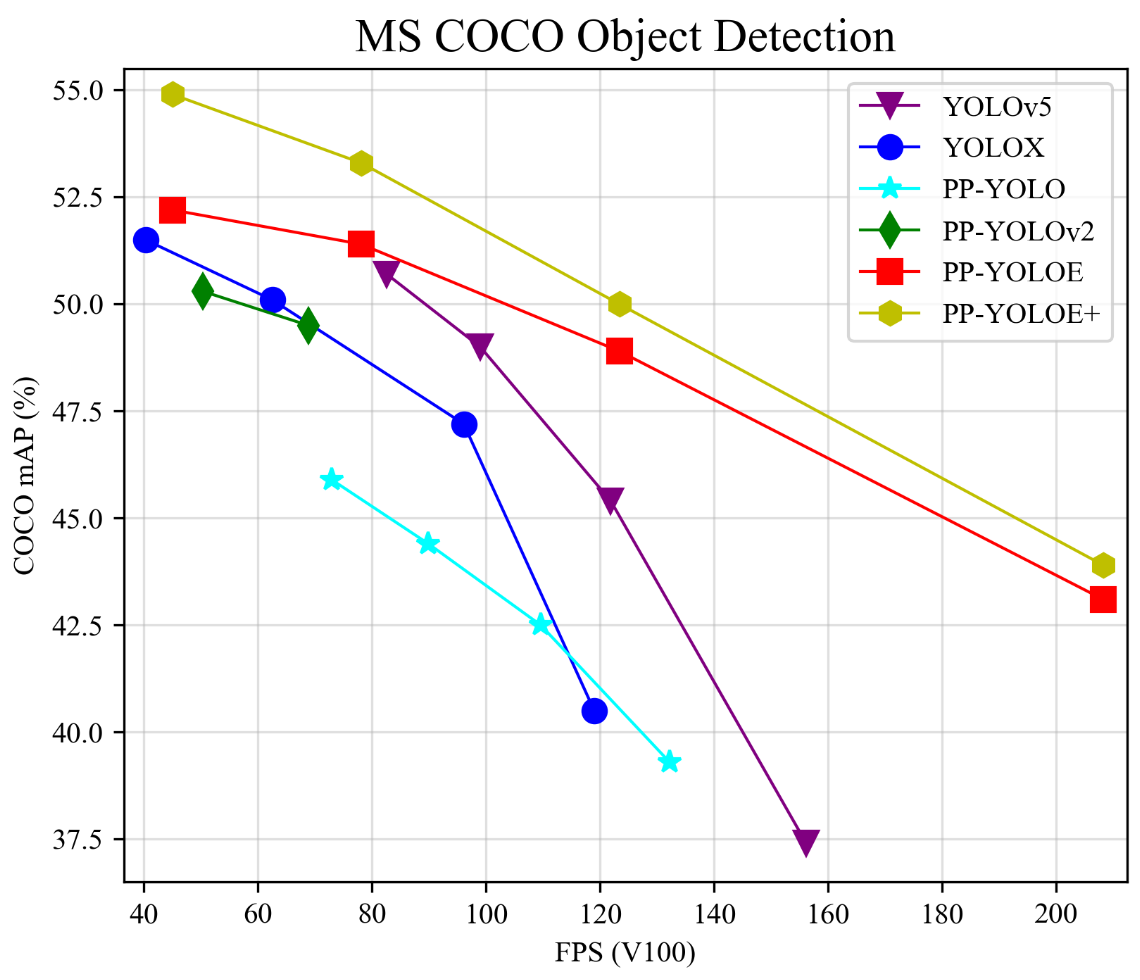
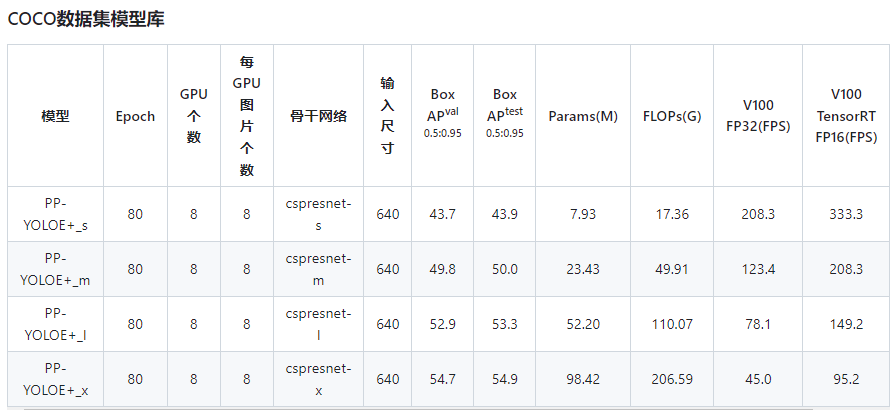
2.1 PP-YOLOE+模型介绍
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.6/configs/ppyoloe/README_cn.md
PP-YOLOE是基于PP-YOLOv2的卓越的单阶段Anchor-free模型,超越了多种流行的YOLO模型。PP-YOLOE有一系列的模型,即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免了使用诸Deformable Convolution或者Matrix NMS之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。
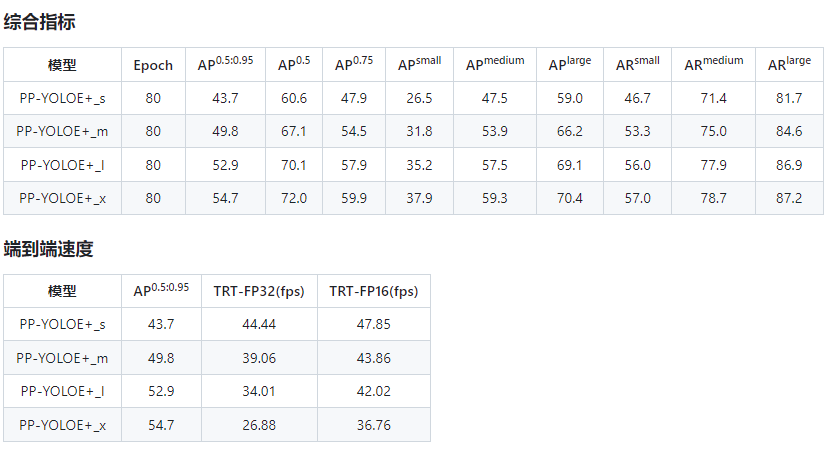
2.2 训练
1 | set CUDA_VISIBLE_DEVICES=0 |
注意:
- 如果需要边训练边评估,请添加
--eval. - PP-YOLOE+支持混合精度训练,请添加
--amp. - PaddleDetection支持多机训练,可以参考多机训练教程.
2.3 评估
模型评估在机器学习和数据分析中起着至关重要的作用。它用于衡量和判断训练出的机器学习模型在现实世界中的性能和表现如何。模型评估的目的是了解模型的预测能力,帮助选择最佳的模型,识别模型存在的问题,以及对模型进行改进。以下是模型评估的一些重要作用:
- 选择最佳模型: 在训练过程中,往往会尝试多个不同类型的模型,如线性回归、决策树、神经网络等。模型评估可以帮助确定哪种模型在给定任务上表现最佳,从而为实际应用中的预测提供更准确的结果。
- 泛化能力检验: 模型在训练数据上可能表现出色,但真正的挑战在于它在未见过的数据上的表现。模型评估可以帮助判断模型是否具有良好的泛化能力,即是否能够对新的数据进行准确的预测。
- 问题识别和解决: 通过模型评估,可以发现模型存在的问题,如欠拟合、过拟合等。这有助于调整模型的参数、特征工程方法或者采集更多的数据,从而改进模型的性能。
- 调整超参数: 模型中的超参数(不由模型自己学习的参数)对模型的性能有重要影响。通过模型评估,可以选择最优的超参数设置,以获得更好的性能。
- 决策支持: 在许多实际应用中,模型的预测结果可能会影响重要决策。模型评估可以帮助评估模型的可靠性,从而为决策提供支持。
- 对比不同模型: 在某些情况下,可能需要比较不同模型的性能。模型评估可以提供有关各个模型优劣的信息,以便选择最适合特定任务的模型。
常见的模型评估指标包括准确率、精确率、召回率、F1 分数、AUC-ROC 曲线等,具体选择哪些指标取决于任务的性质。总之,模型评估有助于确保机器学习模型在实际应用中能够达到预期的效果,提高模型的实用性和可靠性。
1 | python tools/eval.py \ |
2.4 推理
1 | CUDA_VISIBLE_DEVICES=0 |
2.5 模型导出
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 在PaddleDetection中提供了 tools/export_model.py脚本来导出模型
1 | python tools/export_model.py \ |
预测模型会导出到inference_model/yolov3_mobilenet_v1_roadsign目录下,分别为infer_cfg.yml, model.pdiparams, model.pdiparams.info,model.pdmodel 如果不指定文件夹,模型则会导出在output_inference
3. 推理
3.1 用导出后的模型进行推理
1 | python deploy/python/infer.py \ |
3.2 使用摄像头推理预测
1 | python deploy/python/infer.py \ |