机器学习与深度学习:基础与历史
什么是机器学习?
机器学习(ML)是一种解决问题的方法,其特点在于解决那些由于高昂的人工编程成本而不适合由人类程序员手动开发算法的问题。相反,机器学习让机器能够通过自行”学习”和”发现”算法来解决这些问题,而不需要明确告知机器要执行什么任务。近年来,生成人工神经网络已经超越了许多传统方法的成果。机器学习方法已广泛应用于多个领域,包括大型语言模型、计算机视觉、语音识别、电子邮件过滤、农业和医学等,以降低开发特定任务算法的成本。
机器学习的数学基础主要依赖于数学优化方法,同时也与数据挖掘领域有关,后者主要关注通过无监督学习进行数据探索性分析。
机器学习因其能够应用于各种业务问题而受到广泛关注,有时也被称为预测分析。虽然并非所有机器学习方法都基于统计学,但计算统计学在该领域的方法中起着重要作用。
机器学习与传统编程的区别?
机器学习更适用于那些难以用传统编程方法解决的复杂问题,尤其是涉及大量数据和需要自适应性的情况。传统编程仍然在许多应用中有其价值,但在需要从数据中提取知识和模式的情况下,机器学习通常更为强大和灵活。
传统编程要求程序员编写明确的规则和算法来解决问题,这些规则基于程序员的先验知识和理解,通常包括详尽的逻辑和条件语句。然而,机器学习不需要明确的规则,而是允许计算机系统从数据中学习模式和规律,然后根据学到的知识执行任务。这使机器学习系统能够根据输入数据自动调整行为,无需程序员明确编写规则。
机器学习是数据驱动的,依赖于大量的数据,系统从中学习并使用这些模式来做出决策或预测未来的结果。机器学习模型通常更通用和适应不同情境,一旦训练完成,它们可以用于解决未见过的问题。此外,机器学习适用于处理大规模和复杂的数据,尤其在需要自适应性的情况下表现出色。总的来说,机器学习在解决复杂问题和从数据中提取知识和模式方面更为强大和灵活,而传统编程仍然在许多应用中有其价值。
什么是深度学习?
深度学习是机器学习的一个子集,由三层或多层神经网络组成。 神经网络试图通过从大数据集中学习来模拟人脑的行为。 深度学习推动了许多人工智能应用的发展,这些应用改善了系统和工具提供服务的方式,例如语音技术和信用卡欺诈检测。
机器学习使用算法驱动的数据重新处理,而深度学习则努力通过历史数据来模仿人脑以产生准确的预测。 深度学习算法在学习过程中,每次都会不断调整自己以获得更好的结果。 这些算法依赖大量数据来驱动学习。
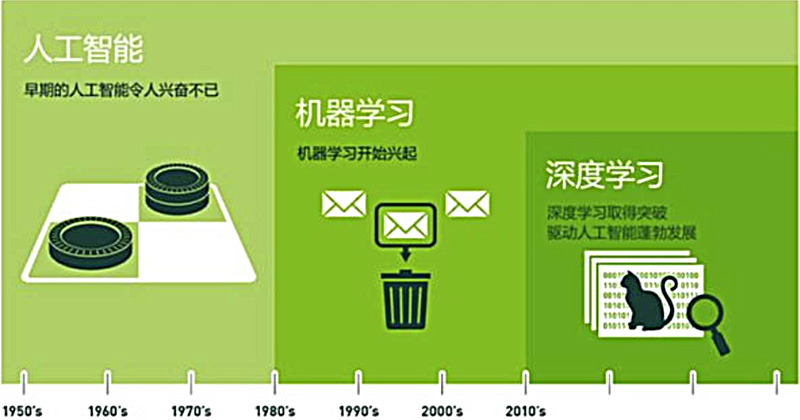
人工智能(AI)、机器学习(ML)和深度学习(DL)历史与发展
作为初学者,很有必要去了解一下关于人工智能、机器学习和深度学习的历史,只因这些概念在现代社会扮演着至关重要的角色。我们可以观察到,众多技术产品已经紧密依赖这些人工智能,这一现象都归因于计算机技术和算法的不断进步,从而引发了巨大的工业需求。因此,越来越多的企业都在试图抓住这一波技术浪潮。
然而,令人惊奇的是,这些人工智能领域的根源可以追溯到20世纪40年代初期,而试图追溯到单一的发明者并不切实际。人工智能领域的发展通常是由多个人的集体努力的成果,他们在算法、方法、框架等方面做出了独特的贡献。因此,人工智能和机器学习的历史是一个引人入胜的话题。
让我们一同进行一次时间旅行,深入了解这些概念的起源,以及它们如何逐渐成为我们日常生活不可或缺的一部分。
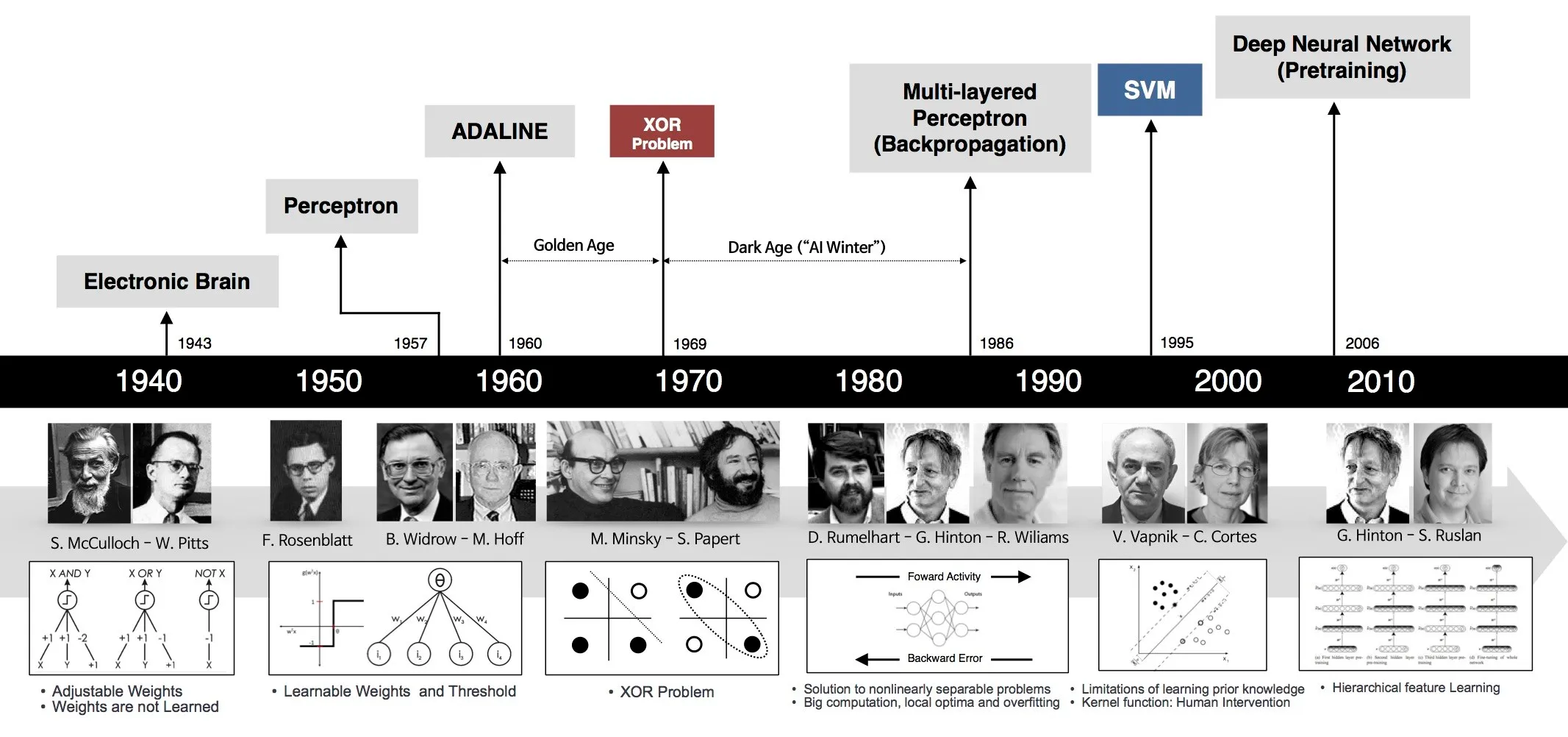
1943年 神经网络的首次数学表示

沃伦·斯特吉斯·麦卡洛克(Warren Sturgis McCulloch),一位神经生理学家,和沃尔特·哈里·皮茨(Walter Harry Pitts),一位逻辑学家,提出了神经网络的第一个数学模型。他们的工作目的是模仿人类思维过程。这个提出的模型也被称为McCulloch-Pitts神经元。
1949年 行为的组织:一种神经心理学理论


1949年,心理学家唐纳德·奥尔丁·赫布(Donald Olding Hebb)出版了书籍《行为的组织》。这本书讨论了行为与神经网络和大脑活动之间的关系。后来,它成为机器学习的基石之一。
1951年 第一个人工神经网络
1951年,马文·明斯基(Marvin Minsky)与迪恩·埃德蒙兹(Dean Edmonds)合作构建了第一个人工神经网络,模拟老鼠穿越迷宫的过程。
他们设计了第一台神经计算机,名为SNARC(随机神经模拟强化计算机)如图5,由40个神经元组成。这些神经元具备短期和长期记忆,并能够根据完成特定任务(采用赫布学习原则)的成功程度来调整它们之间的连接强度(突触权重)。这台机器由管子、电机、离合器等组件构建而成,成功地模拟了老鼠在迷宫中寻找食物的行为。

当明斯基还是一名学生时,他梦想着创造一台机器,它能够通过与突触相连的记忆神经元来学习,并具备过去的记忆,以在面对不同情境时有效地运作。
在1951年,这一梦想成为现实,他们创建了一个机器,它由迷宫般的阀门、小型电机、齿轮和连接各个神经元的电线组成。某些电线随机连接到存储器,以模拟事件之间的因果关系。他们组装这台机器的原因是为了寻找迷宫的出口,机器在迷宫中充当老鼠的角色,而机器的进展则通过光网络进行监控。
一旦系统建立,他们能够跟踪迷宫中“老鼠”的所有移动。由于设计缺陷,他们发现可以引入不止一只“老鼠”,它们开始相互交互。经过各种尝试后,这些“老鼠”开始进行逻辑思考,通过强化正确选择来帮助它们前进,随后更优秀的“老鼠”会被其他“老鼠”跟随。这个早期实验是明斯基在迪恩·埃德蒙兹的协助下创建的,涉及了许多随机连接,就像一个神经系统,能够克服其中一个神经元故障导致的信息中断。
1952年 机器学习的远见

艾伦·图灵(Alan Turing)是一位著名的数学家,因在第二次世界大战期间解密德国恩尼格玛机的加密而闻名,同时他提出了著名的图灵测试,奠定了人工智能的基础。后来,他在自己的工作中预测了机器学习的发展。他在《计算机与智能》一文中提到了图灵测试,该测试的目的是判断一台机器是否具备思维能力。
1952年 亚瑟·李·塞缪尔(Arthur Lee Samuel)首次提出了“机器学习”这个术语

计算机科学家亚瑟·李·塞缪尔(Arthur Lee Samuel)是人工智能领域的先驱者。他成功地让计算机能够通过经验来学习。在IBM工作期间,他制定了第一个机器学习算法,用于下跳棋游戏。这个算法是特殊的,每次移动后,计算机都会变得越来越好,纠正错误,并从数据中找到更可靠的获胜方式。这款游戏是机器学习的早期示例之一。
1956年 达特茅斯研讨会

1956年的达特茅斯夏季人工智能研究项目被广泛认为是人工智能领域的创始事件。这个项目持续了大约六到八周。在这个研讨会上,来自数学、工程、计算机和认知科学等领域的杰出科学家进行了一场有关人工智能和机器学习研究的头脑风暴会议。
1957年 播下深度神经网络的种子

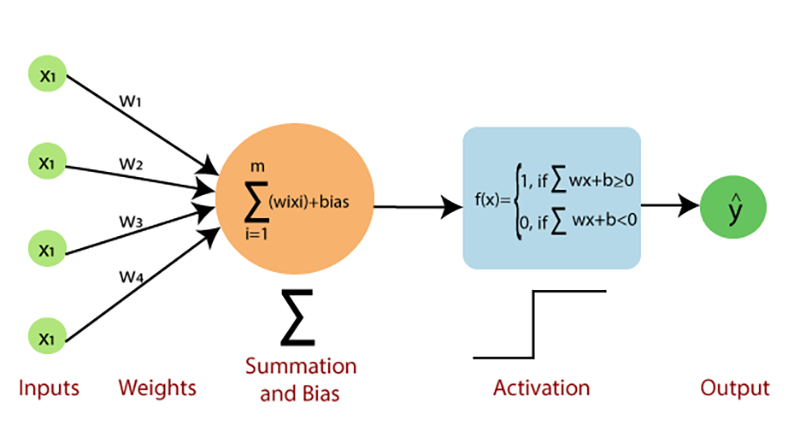
弗兰克·罗森布拉特(Frank Rosenblatt)是人工智能领域的杰出心理学家。他在1957年发表了一篇题为“感知和识别自动装置的感知器(The Perceptron: A Perceiving and Recognizing Automaton)”的论文。在这篇论文中,他讨论了一个电子或电机系统的构建。这个系统的目标是以几乎与生物大脑的处理方式相媲美的方式,学习和理解光学、电气或声音数据的模式之间的相似性或对应关系。
1959年 视觉皮层中细胞的发现

两位神经生理学家大卫·亨特·休贝尔(David Hunter Hubel)和托尔斯滕·尼尔斯·维塞尔(Torsten Nils Wiesel)合作,共同发现了视觉皮层中的两种类型的神经元:简单细胞和复杂细胞。他们的研究启发了各种形式的人工神经网络的制定。
1960年 连续反向传播的基础

亨利·J·凯利(Henry J. Kelley)是航空航天和海洋工程领域的教授。他撰写了一篇名为“最佳飞行路径的梯度理论”(Gradient Theory of Optimal Flight Paths)的论文。在这篇研究论文中,他讨论了具有输入的系统的行为以及如何根据反馈更新系统行为。这一概念为连续反向传播的基础奠定了基础,而连续反向传播是多年来用来降低神经网络损失的重要特性。
1965年 多层感知器

数学家亚历克西·伊瓦赫内尔科(Alexey Ivakhnenko)和瓦伦廷·拉帕(Valentin Lapa)建立了一个可工作的深度学习网络。这个网络有时也被称为第一个多层感知器。该网络使用多项式激活函数,并通过使用数据处理方法的群体(GMDH)来进行训练。GMDH指的是一组关于多参数的计算机数学模型的归纳算法,其结构完全自动化。该算法使用深度前馈多层感知器,在每一层使用统计方法来获取最佳特征并将其传递到网络中。
1967年 最近邻算法

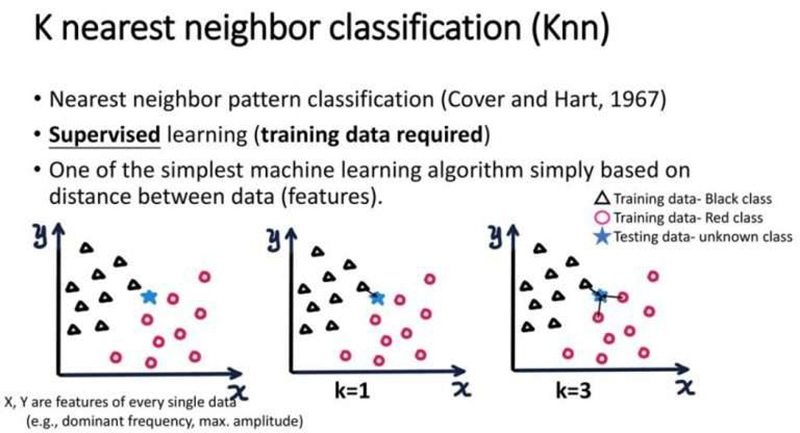
信息理论家托马斯·M·科弗(Thomas M. Cover)和计算机科学家彼得·E·哈特(Peter E. Hart)在1967年发表了一篇关于最近邻算法的论文,发表在IEEE上。最近邻算法是用于分类的基本决策程序之一。它根据样本的最近邻居的类别对样本进行分类。
1979年 神经网络学会识别图像-卷积神经网络
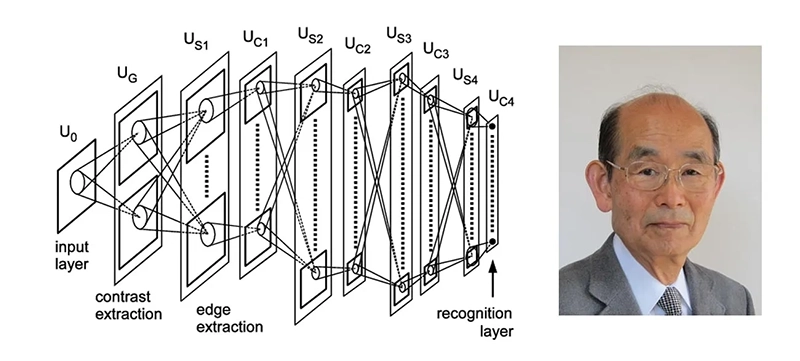
计算机科学家福岛邦彦(Kunihiko Fukushima)以其关于Neocognitron的研究而广受认可。Neocognitron是一个多层神经网络,用于识别图像中的模式。这一框架已经被用于识别手写模式、推荐系统和自然语言处理。在接下来的几年里,他的工作有助于构建第一个卷积神经网络(CNNs)。
1982年 关联神经网络

科学家约翰·约瑟夫·霍普菲尔德(John Joseph Hopfield)以其在关联神经网络领域的工作而广受认可。这是一种受到大脑中神经网络相关性功能和结构启发的集成方法。该方法通过模拟神经网络的短期和长期记忆来运行。
1985年 编写一个程序:与婴儿相同的方式英文单词发音

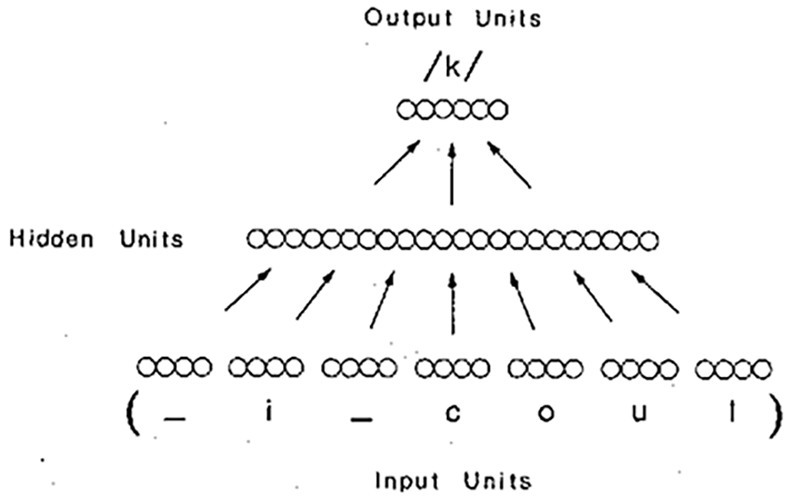
计算机研究员特里·塞恩诺斯基(Terry Sejnowski)以将生物学和神经网络领域的专业知识相结合而闻名。在1985年,他创建了NETtalk,这是一个旨在以类似婴儿的方式发音英文单词并随着时间提高效率的程序。
1986年 通过反向传播错误学习表示

大卫·鲁梅尔哈特(David Rumelhart)是一位心理学家,杰弗里·辛顿(Geoffrey Hinton)是一位计算机科学家,罗纳德·威廉斯(Ronald J. Williams)是一位教授。他们共同于1985年撰写了一篇名为“通过反向传播错误学习表示”的论文。该论文详细讨论了反向传播的原理,解释了它如何可以增强神经网络,如人工神经网络(ANNs)、卷积神经网络(CNNs)等,以执行多种任务。
1986年 限制玻尔兹曼机(Restricted Boltzmann Machine,RBM)

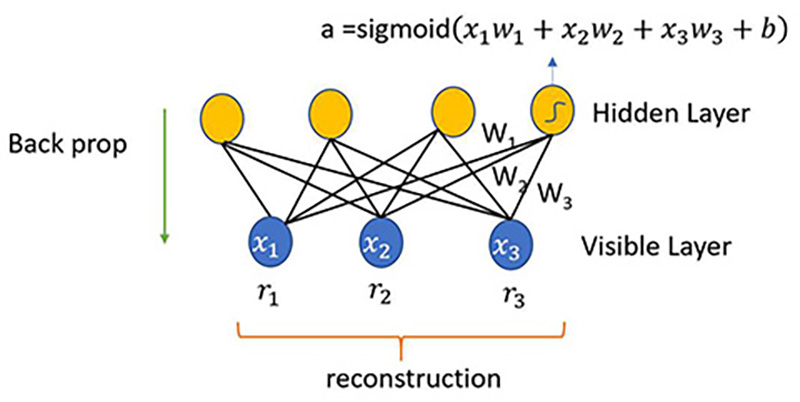
认知科学家保罗·斯莫伦斯基(Paul Smolensky)引入了限制玻尔兹曼机(Restricted Boltzmann machine)的概念。限制玻尔兹曼机是一种生成性随机人工神经网络,可以学习其输入集上的概率分布。这一算法在降维、分类、回归、协同过滤、特征学习和主题建模等领域非常有用。
1989年 使用反向传播网络进行手写数字识别

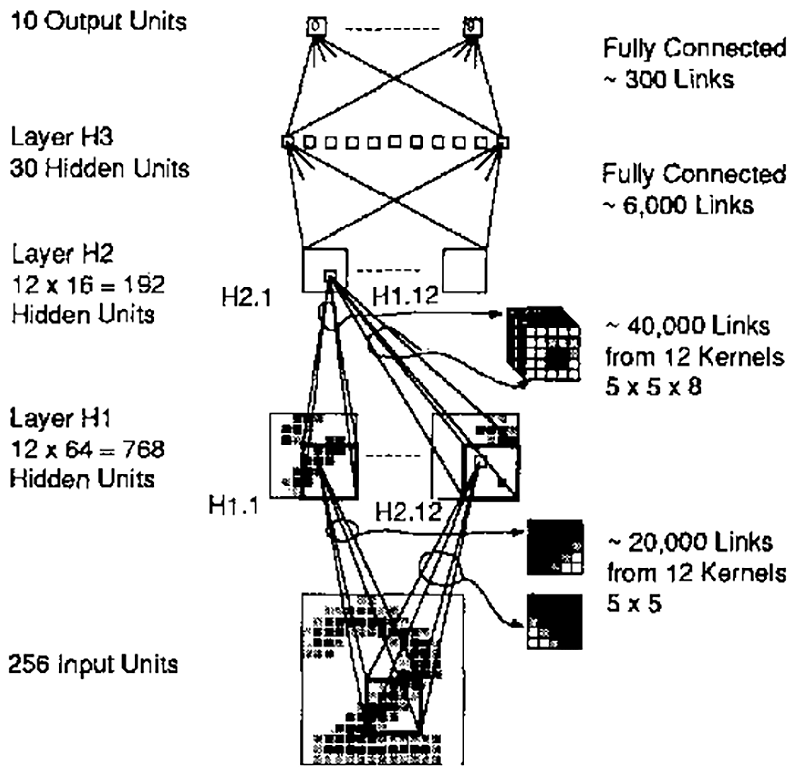
计算机科学家杨立昆(Yann André LeCun)在1989年利用卷积神经网络和反向传播的概念来读取和识别手写数字中的模式。
1989年 Q学习理论
![12855_v9_bb[1]](/images/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E4%B8%8E%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80%E4%B8%8E%E5%8E%86%E5%8F%B2/assets/images.jfif)

克里斯托弗·沃特金斯(Christopher Watkins)于1989年撰写了关于延迟奖励学习的论文。他提出了Q-learning的理论,极大地改进了强化学习的实用性和可用性。这一算法具有在不表示马尔可夫决策过程的转移可能性的情况下直接学习最优控制的潜力。
1995年 支持向量机(SVM)

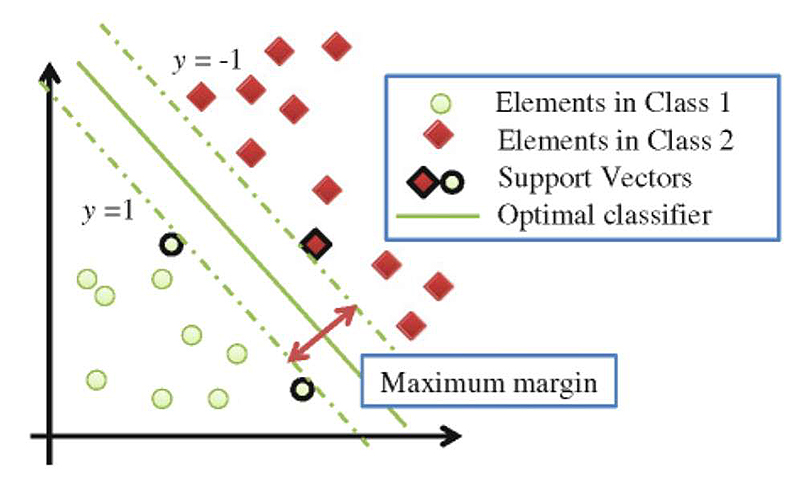
尽管支持向量机(SVM)自上世纪60年代以来就存在,但计算机科学家科琳娜·科尔特斯(Corinna Cortes)和弗拉迪米尔·诺莫维奇·瓦普尼克(Vladimir Naumovich Vapnik)在1995年发展了当前标准的SVM模型。支持向量机(SVM)是一种用于分类和回归问题的线性模型。它可以解决线性和非线性问题,并在许多实际问题中表现良好。SVM的思想很简单:该算法创建一条直线或一个超平面,将数据分隔成不同的类别。
1995年 随机决策森林

计算机科学家何天琴(Tin Kam Ho)于1995年引入了随机决策森林(Random Decision Forests)的概念。随机森林或随机决策森林是一种用于分类、回归和其他任务的集成学习方法,它在训练时生成多棵决策树。对于分类任务,随机森林的输出是大多数树选择的类别。
1997年 长短时记忆(Long Short-Term Memory,LSTM)

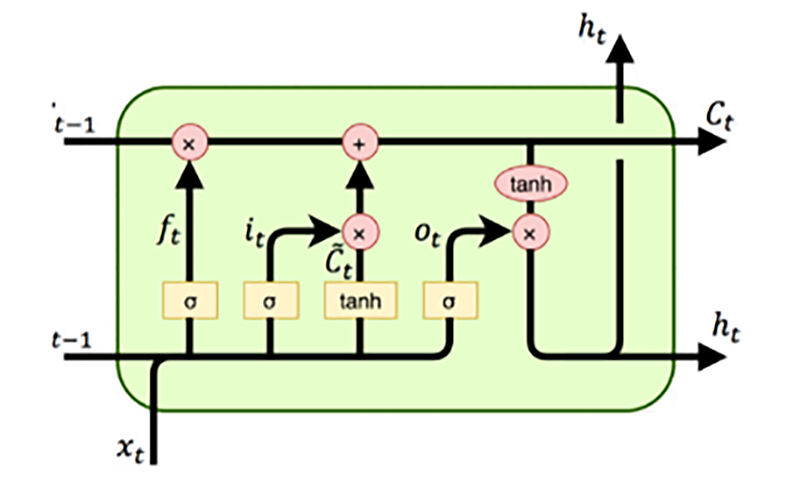
1997年,两位计算机科学家尤尔根·施密德胡贝尔(Jürgen Schmidhuber)和约瑟夫·塞普·赫赫赖特(Josef Sepp Hochreiter)引入了长短时记忆(Long Short-Term Memory,LSTM)。他们通过解决长期依赖性问题,提高了递归神经网络的效力和实用性。长短时记忆是深度学习领域中使用的一种人工递归神经网络架构。与标准的前馈神经网络不同,LSTM具有反馈连接,可以处理不仅是单个数据点,还有整个数据序列。
1997年 计算机击败了加里·卡斯帕罗夫(Garry Kasparov)
![1377289976000-AP-B02G1CHESS05-32P8-X-27-LINES[1]](/images/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E4%B8%8E%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80%E4%B8%8E%E5%8E%86%E5%8F%B2/assets/1377289976000-AP-B02G1CHESS05-32P8-X-27-LINES.webp)
IBM计算机Deep Blue在一场国际象棋比赛中击败了国际象棋大师加里·卡斯帕罗夫(Garry Kasparov)。这一事件证明了机器的智能正在赶上人类的智能。
2009年 ImageNet一个带标签图像的数据库
计算机科学家李飞飞(Fei-Fei Li)启动了一个庞大的带标签图像数据库“ImageNet”。她扩大了可用于训练算法的数据,因为她认为人工智能和机器学习需要大规模的训练数据,以匹配真实世界的情境。该数据库包含了1,419,7122张带标签的图像,供研究人员、教育工作者和学生使用。
2012年 AlexNet网络模型
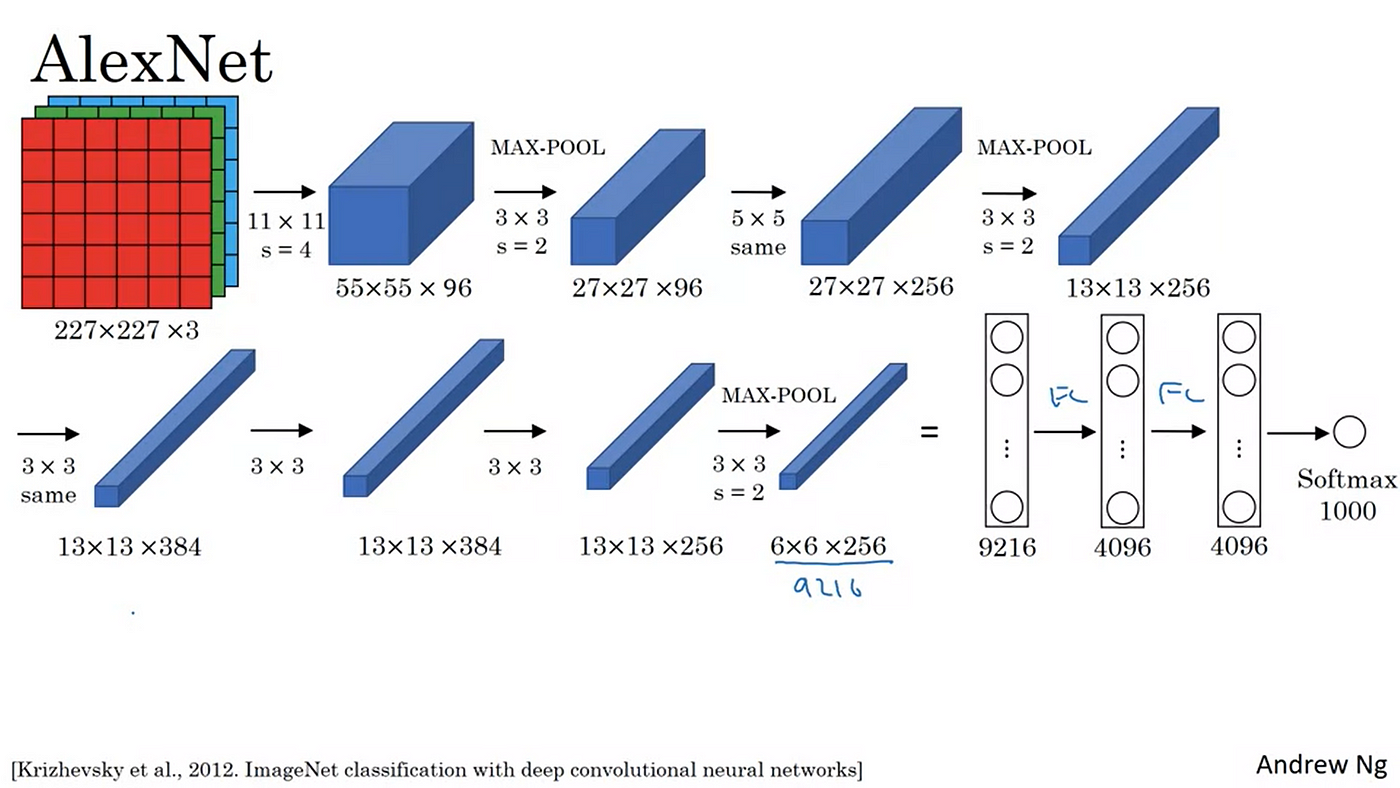
计算机科学家亚历克斯·克里日夫斯基(Alex Krizhevsky)以他在人工神经网络和深度学习领域的工作而闻名。在2012年,他引入了AlexNet,它在LeNet-5的基础上进行了改进。最初,它只包含了八个层次 - 五个卷积层,然后是三个使用修正线性单元的全连接层。
2012年 Google Brain学会识别照片上的猫

该公司的联合创始人、斯坦福大学计算机科学教授 吴恩达 说:“我们办公室周围有很多白板,这些想法都被写下来、删除、写下来和删除。
拥有综合的机器学习环境,Google X 实验室构建了一个名为Google Brain的人工智能算法。在2012年,该架构在图像处理方面表现出色,能够识别照片中的猫。他们的网络经过随机选取的1000万张未标记图像进行训练。该网络能够以74.8%的准确率识别猫的图像。
2014年 生成对抗网络(Generative Adversarial Networks,GAN)

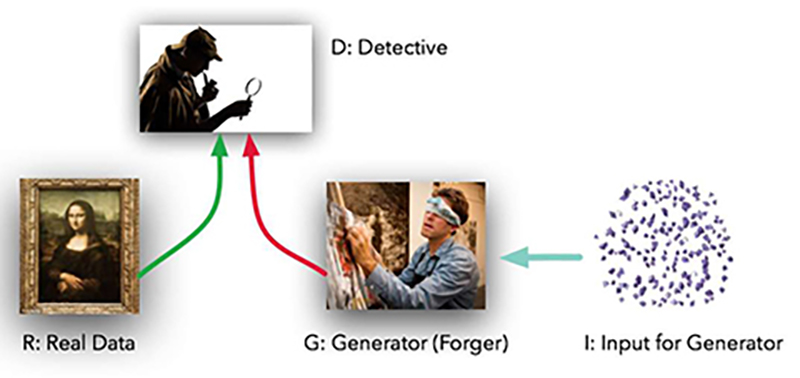
伊恩·J·古德费洛(Ian J. Goodfellow)是一位研究员,他的团队在2014年引入了生成对抗网络(Generative Adversarial Networks,GAN)。生成对抗网络可能是人工智能领域中最强大的算法之一。生成对抗网络(GAN)是一种机器学习模型,其中两个神经网络相互竞争,以提高其预测的准确性。GAN通常以无监督方式运行,使用合作的零和博弈框架来学习。
2014年 DeepFace系统

2014年,Facebook研究团队构建了DeepFace。这是一个深度学习面部识别系统,由一个包含九层的神经网络组成,经过在Facebook用户的400万张图像上训练。这个神经网络可以以97.35%的准确度在图像中识别人脸。
2014年 Chatbot聊天机器人

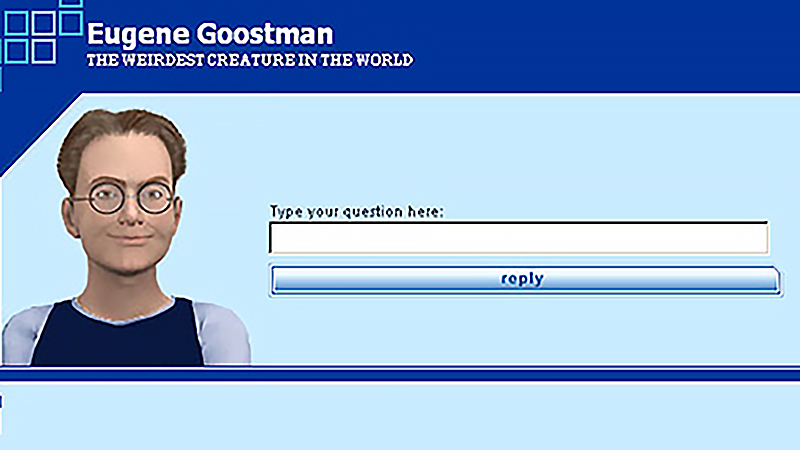
在2014年,弗拉基米尔·维塞洛夫(Vladimir Veselov)、尤金·德姆琴科(Eugene Demchenko)和谢尔盖·乌拉辛(Sergey Ulasen)开发了第一个聊天机器人,命名为尤金·古斯特曼(Eugene Goostman)。有人认为它已经通过了图灵测试,这是一项测试计算机是否能够与人类无法区分地进行交流的能力。古斯特曼被描绘成一个13岁的乌克兰男孩,具有故意引起与其互动者宽容的特征,因为它存在语法错误和缺乏一般知识。
2016年 Face2Face

一群科学家在2016年的计算机视觉与模式识别大会上介绍了Face2Face。这是一种用于单目标视频序列的实时面部再现方法。源序列也是通过普通网络摄像头实时捕捉的单目录视频流。
2018年 BERT语言模型
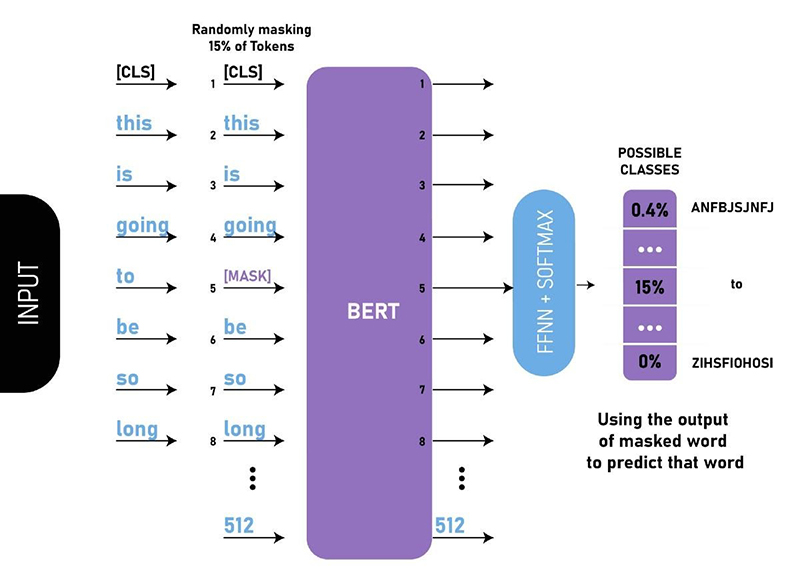
在2018年,Google开发了BERT(Bidirectional Encoder Representations from Transformers),这是第一个双向无监督语言模型。它可以使用迁移学习执行多种自然语言处理任务。